Is PDF chaos on your mind? Is your Digital system insane in the membrane?
This is the second post of the series Digital Workflows for Academic Research on the Mac, and it’s, for lack of a better phrase, about taming your wild wild west world of unorganized PDFs, rogue USB drive sticks, and general lack of a organized digital system. You may not realize how much of a mess your digital world may be, and if you are a pristine PDF organizer already, offer your comments at the end of todays post on how you keep it all together–I’d like to encourage discussion on this since my way is not the only way. Here I offer some general principles.  But first, let’s think to the old “analog” world of things.
But first, let’s think to the old “analog” world of things.
If your desk looks like that, you may very well be a creative genius. You may very well be that person who can legitimately claim that “it looks messy, but there’s a method to the madness.” If your desk is always perfect, you’re likely to say, “what a mess! that is madness.” Now, even if such a pile is evidence of your genius; even if this pile did once contribute to a flourish of genius and a final product, in this current state of chaotic “pileness,” I hardly believe it would be any use to you now for future consultation without sorting, collating, and long term organizing. If you were ever to need these files again to generate new ideas, or for reference, you would need to sort through this pile of papers, notebooks, print outs, newspapers, and books again into some sort of filing system to make it serviceable it again for a project. Until that happened, and you need to restore order to the pile, the pile would literally be “on your mind.”
In fact, for David Allen, the Getting Things Done guru, “your mind is about having ideas not holding them,” and one of the first tasks he recommends in implementing his GTD system is for aspirants to stress-free productivity to physically account for every single object in their desk and home office space (check out his TED talk). For Allen, loose papers, and chaotic piles of reading material can constitute what he calls “open loops” that drain our mental focus and energy–and the small behaviors that rein them in can feel “awkward”, “unnatural,” and even “unnecessary.” They only cease to be overwhelming “open loops” when we put the things into buckets and containers, and consciously decide if they are important for a project, and then wheher or not they are actionable as a step in realizing that project. In Getting Things Done (2003, 13), Allen describes these generally in terms of “commitments,” but the general behaviors are worth mentioning for us in terms of PDF workflow basics–perhaps for us we could call them “reading, writing, and research commitments”:
Managing commitments well requires the implementation of some basic activities and behaviors: First of all, if it’s on your mind, your mind isn’t clear. Anything you consider unfinished in any way must be captured in a trusted system outside your mind, or what I call a collection bucket, that you know you’ll come back to regularly and sort through. Second, you must clarify exactly what your commitment is and decide what you have to do, if anything, to make progress toward fulfilling it. Third, once you’ve decided on all the actions you need to take, you must keep reminders of them organized in a system you review regularly.
For Allen, we are foolish to depend on our psyche as a system to manage the mess of projects and things of our creativity. If so we lose perspective and ability to put our focus on what we need; we lose both control and the stability we need to keep our attention on the processes and tasks necessary to accomplish (realize) our goals.
What system? You mean, like, an operating system?

Now since the whole development of the GUI (Graphical user interface) and WYSIWYG (What you see is what you get) interface back at the Xerox Parc research center, and even before that, Ivan Sutherland’s Sketchpad (1963)–which produced the concept behind the user interface we are so familiar with in the Microsoft Windows and Apple Macintosh operating systems–we have to remember that even leaving the whole problem of apps aside (see my previous post), the “operating system” was from the beginning entirely modeled off the the banality of “files,” “folders,” and note “tags” of the analog office process of the pre-digital, “paper pushing” era. Indeed this is still a valid model for all productivity and workflow (see Merlin Mann’s 43 Folders), especially in academics. In his Laws of Media: The New Science (1992), Marshall McLuhan, pointed out that the new media technology as tool forms are always an extension of our body or sensual organs. As much as a “mouse” is a bodily input device, so the folder is a digital collection bucket. In this sense, the “file,” “folder,” and “tag” concept, which Macademic has recently blogged on, is still very much an old concept–despite the recent and beneficial craze about tagging–and highly relevant to what I say here about bringing order to PDF chaos: just as you would need to have a system for naming files, filing them, categorizing them, and “tagging” them in an analog system–and depend on it consistently every single time–so you need it in its digital equivalent, without looking at the computer as something that it’s not: a semi-autonomous, automatic thing managing machine. When computer technology appears to our consciousness as a quasi autonomous interface or interactive experience–as it often does with our proliferation of apps, devices, and “multimedia”–rather than an extension of our bodies, we easily default to the Google sirens and fall in the gadget trap. We can confuse the “medium” with the “message.” That is, we believe we don’t need to manage our files and apply extensive rational intelligence to it as we would in the paper world. The ability to “Google” or “Spotlight Search” documents creates an illusion or simulacrum of a system, but it is only an operating system, that is an apparatus of files, folders etc. in which a user must use it intelligently and rationally, deploying its tools and structure in regards to process and product. We need to have a process and deliberate collection system.
PDF Workflow. Making it work.

So, it’s okay if you do not have your PDF situation under control, but often a bad PDF situation doesn’t look like it would if it were a real bungle of paper mess, and you can easily be deluded about how orderly things really are, especially given the predilection (I discussed above) we have for thinking we can always “Google” things back into our conscious realm of creativity.
Two years ago I found myself literally drowning in PDFs: PDFs I’d downloaded from JSTOR or other online databases–like Ebsco, PDF excerpts of monographs or chapters of serial publications I’d scanned and OCRed using Abby Finereader in the library for my research, complete PDF books from Google Books or Archive.org, and other forms of ebooks. I realized this chaos was the analog version of a paper mess all over the place (though it disappeared and was easy to hide and consider otherwise) that was interfering with my ability to remember, find, organize, think, and act on the ideas I wanted to develop in my papers and research. Let’s be honest: though the new amazing innovation of technology gave me greater access to obscenely useful quantities of information, I could hardly synthesize and keep my documents together in a way that actually helped me squeeze out a presentation or paper. I was miserable!
Since PDFs are the digital document standard, depending on the equipment used and the number of storage Media involved, it’s clear that you can accumulate a severity of PDF chaos in a short period of time even without much effort at all. Your digital workspace can begin, just by dint of not thinking of a system for Digital Workflows with PDFs, to turn into a big bunch of PDF research “open loops:” some scan stations, to make one example, prompt users to save their PDF files to USB sticks, send to email, or upload to Dropbox. If you’re like me, then you have normally done this on an ad hoc basis–lots of PDFs are somewhere in your Gmail inbox attached to messages, some of them are scattered in various folders of your computer, others here, there, and well, on three different USB sticks–one of which you may have left in a library terminal never to see again. This is further complicated by the fact that files you scan or download may have very diverse file names, some of them “PharosScan(1)” and others the random author or title descriptor you briefly entered in passing, and many simply random digits.
Often, downloading a file from the library begins with non-sensical filenames. For example, from the Columbia’s Library website, I find an article I’d like to download and read.
 What is the file name when I click to download it?
What is the file name when I click to download it?  That’s not entirely helpful, and certainly not anything like PowleyEtAl.2009Enriching.PDF. I doubt I’d remember where it is or that I ever intended to look at it with this name. It’s also not helpful if I have multiple download locations for different browsers. Nor is it helpful if a PDF is not OCRed first, and yet I fail to OCR it, label, and file it immediately. In this case, it turns out my PDF is already OCRed. But if it were not, I’d need to open the document in Finereader or Adobe Acrobat Pro (Devonthink Pro Office, also has an OCR option, which we will discuss later).
That’s not entirely helpful, and certainly not anything like PowleyEtAl.2009Enriching.PDF. I doubt I’d remember where it is or that I ever intended to look at it with this name. It’s also not helpful if I have multiple download locations for different browsers. Nor is it helpful if a PDF is not OCRed first, and yet I fail to OCR it, label, and file it immediately. In this case, it turns out my PDF is already OCRed. But if it were not, I’d need to open the document in Finereader or Adobe Acrobat Pro (Devonthink Pro Office, also has an OCR option, which we will discuss later).
Thou shalt always OCR your PDFs immediately
Every workflow needs to have a system for OCR scanning (optical character recognition), naming, and containing PDFs. Once you have your PDFs scanned, downloaded and OCRed, you also need to have a place where you keep, annotate, and use your PDFs and can name them according to the same parameters every single time (for example, author/date/title); where they can be updated and stored coherently. It’s also important that they never disappear within the proprietary grasp of an application.
So to illustrate the point of (and the magnitude of the mess really depends on what system or lack thereof you have cultivated and how many files you have), I’ve assembled a smattering of PDF files from an old USB stick, and I will eventually show you, in the next post, how Sente can come to the rescue. The rest of this post will simply illustrate some considerations in preparing files for import into your permanent system. As you see, for this demonstration I’ve merely found and downloaded a couple of other files in an old USB stick back up I found on my desk. It perfectly illustrates my pre-workflow lack of a system.
How useful do you find all these random file names? 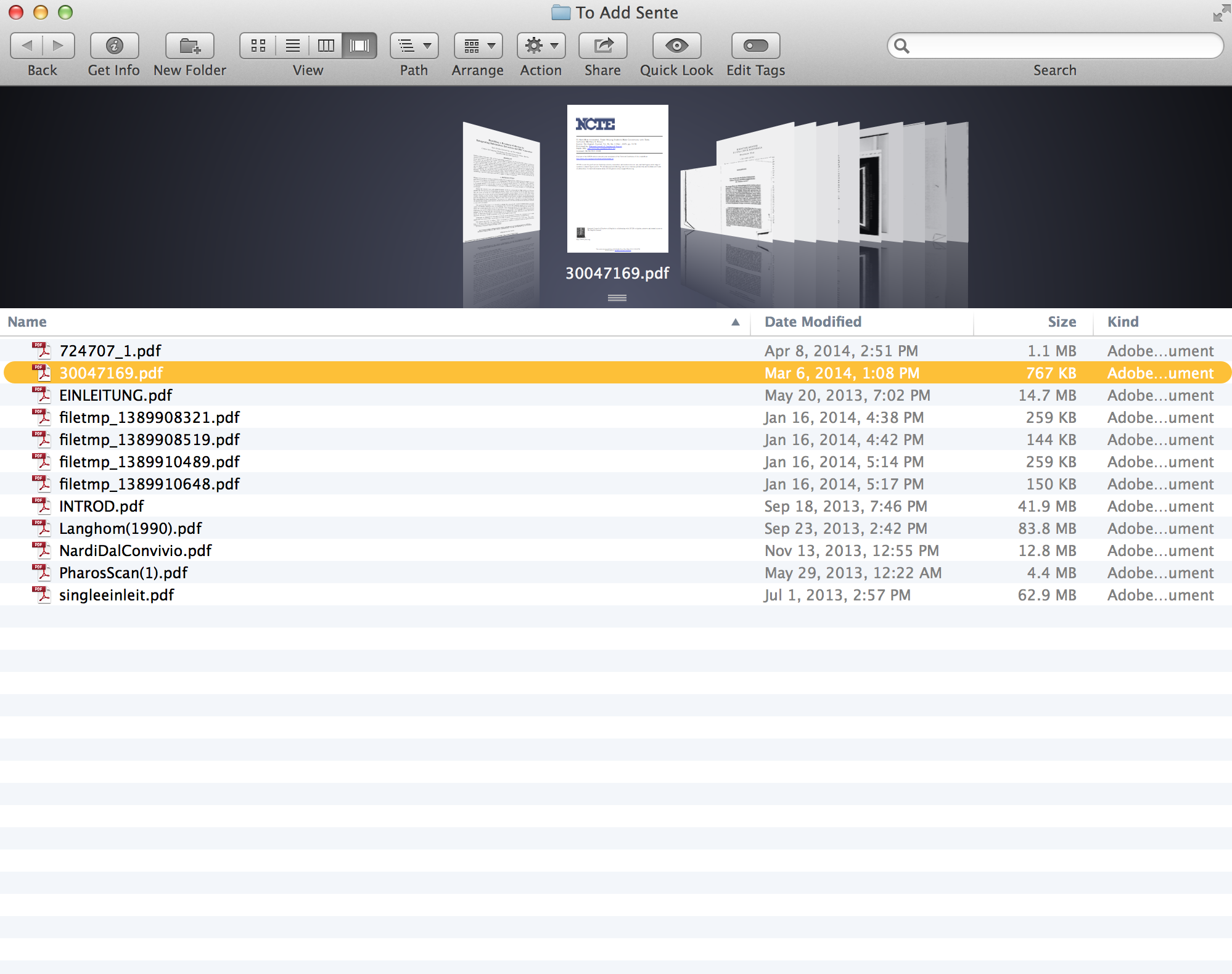 Even if you don’t remember what the hell “filetmp_1389908321.pdf” is, Sente will not only help you remember, but will help you capture its bibliographic record, and allow you to set up a coherent library system for containing it.
Even if you don’t remember what the hell “filetmp_1389908321.pdf” is, Sente will not only help you remember, but will help you capture its bibliographic record, and allow you to set up a coherent library system for containing it.
But before we go there, let’s go ahead and OCR the files, if necessary. This is a must do, first of all, because it is impossible to effectively keyword search, read, annotate, and import the bibliographical information of un-OCRed PDFs, even leaving any applications aside. One of the greatest things about Sente is that it will allow you to almost instantly capture the correct bibliographic information of PDF documents from online databases, re-name, and file the PDFs for you into a usable library. Sure some other software does something similar, but I promise Sente gives you more power and control. In any case, even if you someday opt not to use Sente, OCRing your texts and renaming them is good practice. Now, also remembering our whole above discussion about folders and real files, you also need to create an ‘inbox’ for PDF documents as part of your workflow (In a later post i’ll show you how Devonthink Pro Office lets you automatically import and OCR PDFs–and, additionally, create an intelligent and AI enhanced filing system).
Make a folder on your desktop or in your downloads folder where you’ll keep PDFs that need to be OCRed and then processed into Sente. I’ve called this now “To Add Sente,” in my example. Sente allows you to capture and download PDFs directly using its own browser, but you’ll want an inbox for “to add” files too since you will sometimes want to put them in different libraries or add them to Sente later, if needing OCRing, and if you’re not downloading them directly from a database.
If your PDF is not OCRed, I highly recommend using Acrobat Pro. The Academic license is only about $100, and it is well worth the cost.
OCR With Adobe Acrobat
 Once in Acrobat, open your document. If the text does not highlight, or the text pasting comes out garbled, click Tools, then “text recognition.” Click “in this file.”
Once in Acrobat, open your document. If the text does not highlight, or the text pasting comes out garbled, click Tools, then “text recognition.” Click “in this file.” 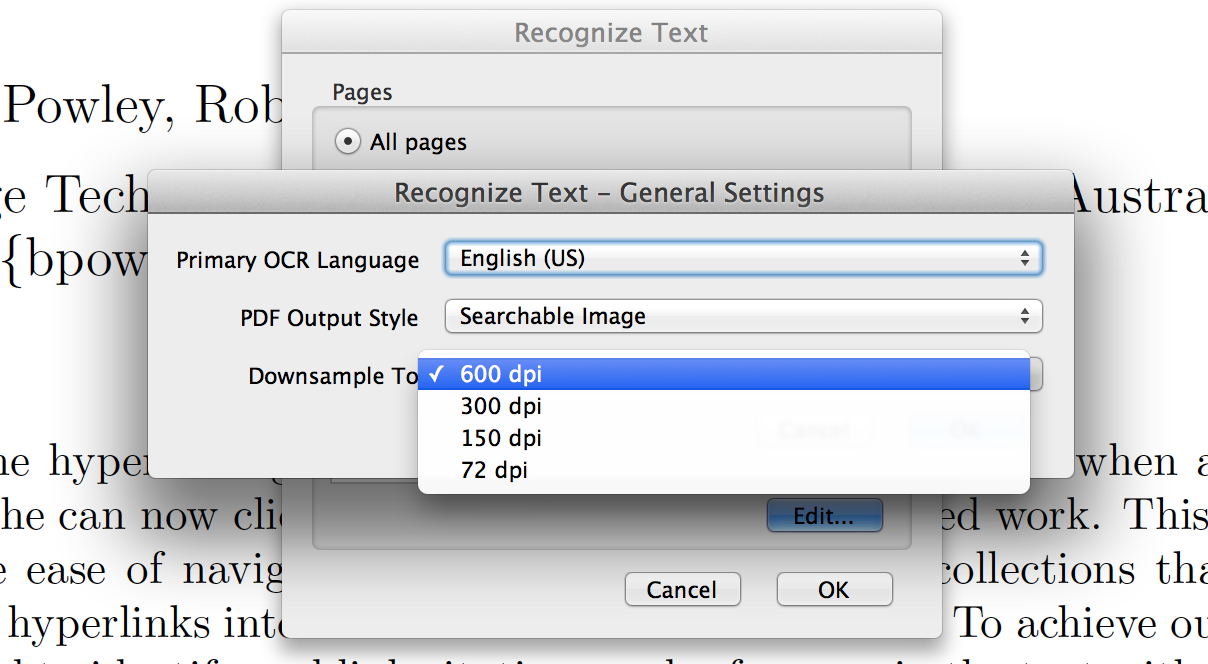 For most needs, 300 dpi is the minimum acceptable on most grayscale texts, while 600 dpi is archive quality. Depending on the power of your CPU and the length of the documents, 600 dpi takes longer, but you will want to run it at 600 if your text has particularly small text and apparatus, in more than one language. Other software, like Abby Finereader on the PC offers options like 400, but since there’s no intermediate here, I usually choose 600. In the example, I select 600 dpi, and choose English as the language (Acrobat allows you to choose from a long list of languages!).
For most needs, 300 dpi is the minimum acceptable on most grayscale texts, while 600 dpi is archive quality. Depending on the power of your CPU and the length of the documents, 600 dpi takes longer, but you will want to run it at 600 if your text has particularly small text and apparatus, in more than one language. Other software, like Abby Finereader on the PC offers options like 400, but since there’s no intermediate here, I usually choose 600. In the example, I select 600 dpi, and choose English as the language (Acrobat allows you to choose from a long list of languages!).
In my example folder, I’ve now OCRed this file. I’ve also checked that all my documents are OCRed. They are, but I come across a particular situation.
Thou shalt spilt your PDFs, and only then OCR them!
Here is a PDF (in German) that I worked from as translator of a monograph.
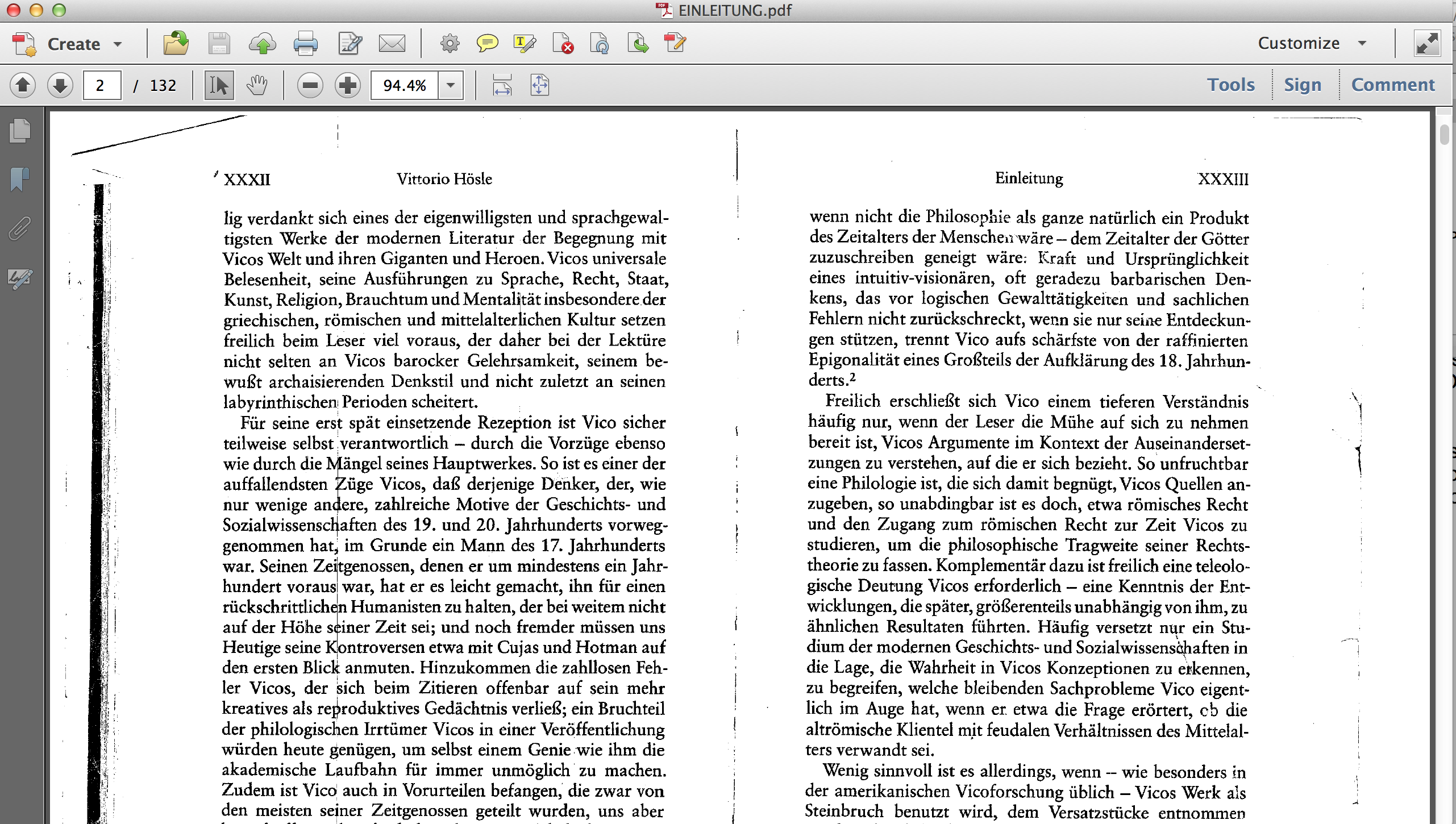
The problem: every one page of the PDF is horizontal orientation, containing in two real book pages. We see the jump here from analog to digital though the scan medium, and the problems it can pose. Most people would find this annoying and think it doesn’t really matter. My opinion is that it does: if you don’t split the document, and re-OCR it you risk:
1) Garbling cited page numbers (John Sidiropoulos has thought about this a lot and it’s important). If you really use and annotate the document in the future, and you cite text on page two that might actually be either real page XXXII or page XXXIII, it’s better if each real page stands for only one page: pg. 2 PDF = XXXII, pg. 3 PDF = XXXIII. This cuts confusion. If you don’t split the PDF now, it is a real pain and gets in the way of your work later.
2) The second risk is that you copy a quote that spills across the entire horizontal page, so for every line of one paragraph on the right, you also get the adjacent line on the left. This is not always the case, but by golly, why bother with that kind of problem?!
It is essential for any workflow to split these dual-paged PDF files. A lot of scan stations automatically do this now, and Finereader does too in the DHC. But if you come across a PDF that is from before this was common, or otherwise find a scan like this, you just need to split it. When you want to cite the page of a PDF, no software will always perfectly number its pagination anyway. There may be a mismatch between the PDF page and the real page of the printed text, just split it so that you can be closer to solving this problem, and save extra confusion. We want things clean and für ewig, to invoke Goethe, which means something like “for all time” in German. Your PDF library is not an ad hoc matter, think about it like your real pristine print library–would want to use real printed books with messed up pagination? Not really.
You want to keep things clean and consistent.
Splitting a PDF
While Acrobat can also split PDFs, I recommend people do this task first always, and use a nifty freeware app called PDF scissors.
 Open your file.
Open your file. 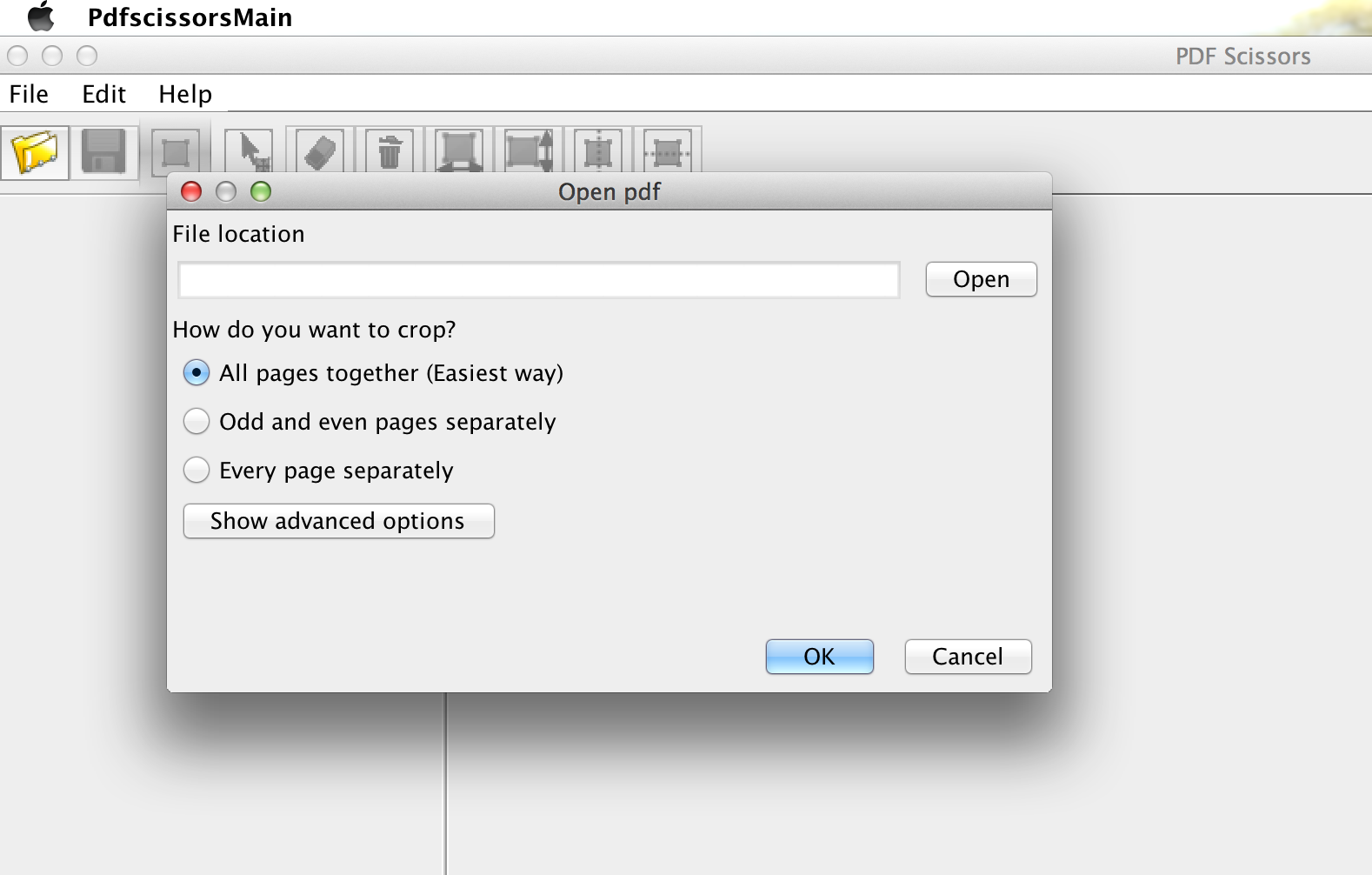 Choose all together. It will then “stack” your file, and allow you to select “crop” into a single PDF. First though, you need to drag a rectangle around the borders of the pages. A safe place to crop is outside the thick overlapped text. You will have to guess exactly where the center of the page is. Usually you will see a clearly darker line in the very center between pages, and in some cases this center is very clear because there is no text in it.
Choose all together. It will then “stack” your file, and allow you to select “crop” into a single PDF. First though, you need to drag a rectangle around the borders of the pages. A safe place to crop is outside the thick overlapped text. You will have to guess exactly where the center of the page is. Usually you will see a clearly darker line in the very center between pages, and in some cases this center is very clear because there is no text in it.  Our new file is now clean, and ready! Once I save the file, here “singleeinleit,” and check it for accuracy, I should delete the double version! Why have a garbage file you might accidentally use then have to think, “where is my split file”?
Our new file is now clean, and ready! Once I save the file, here “singleeinleit,” and check it for accuracy, I should delete the double version! Why have a garbage file you might accidentally use then have to think, “where is my split file”?  This file can then be OCRed in Acrobat and saved.
This file can then be OCRed in Acrobat and saved.
With all of our PDFs split and saved, we are ready to build our Sente library.
In the next post of the series, Using Sente for PDF Management on the Mac and iPad (1): Capturing and Organizing PDFs, I’ll show you how we can use Sente to automatically capture the correct bibliographic information of each PDF, automatically re-name and file each by author, date, and title in a permanent system, and how to index that library bundle for broader use within your operating system, while protecting its integrity.
One thought on “PDF Chaos? Digital Workflow Basics”
Comments are closed.