This is the seventh post in the series Digital Workflows for Academic Research on the Mac for the Columbia Libraries Digital Humanities Center.

In my previous installments on Sente, Sente for PDF Management on the Mac and iPad (1): Capturing and Organizing PDFs, Sente for PDF Management on the Mac and iPad (2): Capturing and Organizing PDFs, Metadata, Tagging, Statuses, and Sente for PDF Management on the Mac and iPad (3): Quick Add, Zotero Workflow, and Automated (Re)searching, I demonstrated the lion-share of Sente’s powerful PDF and reference retrieval and organizational features and got you on the path to setting up your own efficient, and customized library for your academic workflow needs. Before that, in the second post, PDF Chaos? Digital Workflow Basics, I discussed some best practices for staging, splitting, OCRing and setting up your Sente library.
I’d like to thank guest contributor Daniel Wessel for his insightful and comprehensive (re)introduction to the methodology and practice of outlining in scientific writing, Using Content Outlines and Circus Ponies Notebooks for Writing Articles and Theses, which features as the sixth installment of the present Digital Workflows for Academic Research on the Mac and is also viewable on our Butler Library Blog. His contribution is especially valuable and salient to the present post, and I have written this post and planned the next one–which will cover OPML, Text, and Hierarchical Structure: Moving Data between Sente, DEVONThink, CPN, Scrivener and other applications (where I’ll show you how the annotation and reference information in your personal, intertextual archive you’ve built up can be exported–using third part scripts and apps–through OPML/ RTF, and RTFD to a host of different mind map and database applications, plus writing and outlining platforms for such content outlines etc.), also with his post in mind: not only should the three posts be thought of together, but in fact, they basically constitute the peak of the series’ aspiration; namely, helping you move from tools to streamlined processes and well thought out (traditional and hybrid) methodologies which actually allow you to translate your research into realized products: theses, articles, conference papers, and sharable presentations.
The annotation functionality of Sente is its most amazing feature, in my opinion, because it allows you to read and annotate your PDFs–save quotes, make comments, and highlight–and keep them organized and synchronized on your desktop Mac and iPad–and now iPhone (as I was writing this post the new iOS version of Sente was released) through the cloud! Sente is now a one stop solution for you to keep your literature and research at hand at all times. I will also discuss what I call “power note taking,” because Sente operates on a Rich and Plaintext model such that you can easily combine it with a custom tagging system for individual notes–not just references–and even write your individual annotations on captured text in MultiMarkdown first, thus allowing you to tag, use MM syntax, and maintain the integrity of citation keys (for cite and scan). “Power note taking” thus represents making the most of all the tools in the digital humanist tool box for optimizing its use while avoiding any of your hard work being trapped in a single application. By the end of your post I think you’ll be convinced of Sente’s note taking prowess and superiority over Zotero for multiple reasons, not least since it does not yet embed annotations in PDFs, still requires the use of an external editor, and doesn’t take advantage of the simulated book that the iPad and iPhone afford.
The Centrality of Note Taking in Academic Thinking and Research
Note taking is one of the most important and fundamental practices in academic research. Not only does it help you to record, capture, and the collect ideas of others, but the benefits of dialectical thinking truly spring from annotating texts while reading them. The practice and habit of annotation for the majority of academic readers–whether on a separate sheet of paper, sticky notes, subject notebooks, in margins of a book, or in an index-card system of cross-references like Luhmann’s infamous and innovative Zettelkasten, ends up being one’s personal archive of thought and the wellspring for creative intellectual endeavors on the page. Thus note taking is not merely something we do to index and keep track of the ideas of others, but it is an important, deep-seated practice for most academic researchers that ought to be systematized as a kind of extended memory that will serve a lifetime of intellectual work.
Indeed, Luhmann, as the Taking Note Blog points out,
described his system as his secondary memory (Zweitgedächtnis), alter ego, or his reading memory or (Lesegedächtnis). Luhmann’s notecard system is different from that of others because of the way he organized the information, intending it not just for the next paper or the next book, as most other researchers did, but for a life-time of working and publishing. He thus rejected the mere alphabetical organisation of the material just as much as the systematic arrangement in accordance with fixed categories, like that of the Dewey Decimal System, for instance. Instead, he opted for an approach that was “thematically unlimited,” or is limited only insofar as it limits itself.
While there is an app that attempts to replicate the paper Zettelkasten system digitally, there is no doubt that annotation practices have a wide range of complexity and idiosyncrasy such that Zettelkasten wouldn’t work for everyone anyway, and furthermore that they all have varying degrees of adaptability in new media contexts. In any case, most mainstream annotation and reading practices have been made newly complicated on several levels by the realities of and challenges to traditional reading and writing practices in academia and our society–between digital and analog, screen and page, biological and artificial intelligence, political-economic and liberal-arts/humanistic valuations, and a panapoloy of apps, devices, and interfaces. But understanding the dynamics of what is possible with the hybridized nature of the print and print-like form with technology such as iPads, iPhones, Macs and Web 2.0 when applied to evolving traditional, “philologocentric” (if I may) annotation techniques is an advance for the digital humanities in the right direction.
Not only that, but it is really about how the scholar and researcher link together, conceive of, and think about information. Text, in its jump to the cooler hybridized media forms, is still fundamentally hot as a practice, though the text straddles the two domains, and the speed and increased access to text across media means an inherent blending and evolution of hot and cool (I use the McLuhan language playfully, but there is an obvious truth to it. See this and this too, by David Bobbitt on Teaching McLuhan–“…we misconstrue McLuhan’s “hot” versus “cool” distinction when we try to force these terms into static definitions,” for more).
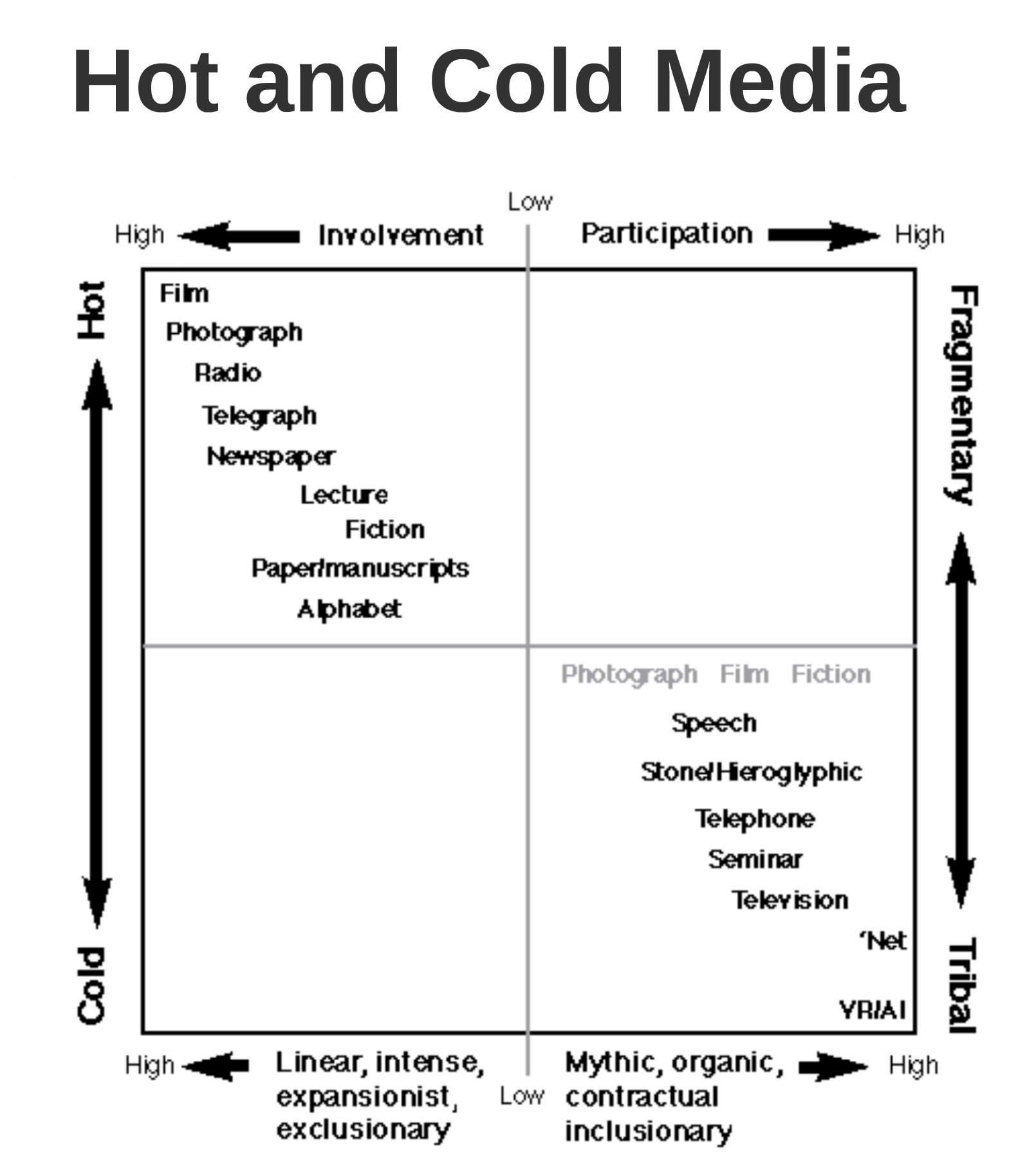
Bridging this is still of key importance.
In fact, it seems this was the motivation behind Ted Nelson’s Xanadu, now released fully after 54 years, which has been thought of as one of the key experiments in hypertext that was a parallel conceptual driver of the world wide web, though Nelson doesn’t quite see it that way. Nelson himself characterized Xanadu as “proposing an entire form of literature where links do not break as versions change; where documents may be closely compared side by side and closely annotated; where it is possible to see the origins of every quotation; and in which there is a valid copyright system– a literary, legal and business arrangement– for frictionless, non-negotiated quotation at any time and in any amount.”
Moerover, Nelson’s Xanadu vision approximates my own aims here in Digital Workflows with PDFs. As the Xandau concept states:
We foresaw in 1960 that all document work would migrate to the interactive computer screen, so we could write in new ways– – paper enforces sequence– we could escape that! – paper documents can’t be connected– we could escape that! – this means a different form of writing – this means a different form of publishing – this means a different document format, to send people and to archive. We screwed up in the 1980s, and missed our chance to be world wide hypertext (the Web got that niche). However, we can still compete with PDF, which simulates paper, by showing text connections.
While I think PDF is the future and the now, Lehmann’s Zettelkasten and Nelson’s Xandau are harbingers of what is already now possible in a well-thought-out workflow using a suite of professional apps, devices, and good practices.
A key part of that, is thinking through a system of note taking and annotation that allows us to efficiently bridge the gap between digital and analog worlds without wasting time and throwing out traditional best practices of reading and annotation with the “bath water.” How do we translate these traditional modes of reading and annotation from this  to the realities of the cloud, multiple devices, and a deluge of electronic practices and receptacles of information?
to the realities of the cloud, multiple devices, and a deluge of electronic practices and receptacles of information?  What is(n’t) digital humanities (and why it matters)?
What is(n’t) digital humanities (and why it matters)?

I want to think about this in a bit more depth, and in terms of the Digital Humanities. In the first post, Introducing Digital Workflows for Academic Research on the Mac I wrote that in the world of Web 2.0, there are tools and apps galore, vast databases of digitized books, articles, shared information, websites, etc. The collection and review of information involves vastly greater quantities of text and also new kinds of media and other crucial information available through the internet which offer incredibly expanded possibilities for research. However, the repository of history and the human sciences not only still predominantly exists on paper and in the library stacks–how many times have you had to scan something in the Digital Humanities Center? raise your hands–but the reality of contemporary research involves a mixture of digital and analog materials and hybridized practices not all of which are equal: a confusing complex in which we–the biological and rational creatures–must work between machines and digital media and yet still adhere to the rightly rigorous demands of linear information presentation and scholastic conventions in the production of papers, articles, and dissertations.
In other words, when it comes to how we think with text (read and work with text) we are talking about an ancient and basic part of the scientific process (note taking and annotation), and thus we are really talking not only talking about how to adapt, but also how to evolve a key and long standing scholarly practice of textual work which inherently involves negotiating convergent practices. Indeed, this is essentially what Presner and Schnapp argue in the Digital Humanities Manifesto 2.0–in an oft cited passage:
Digital Humanities is not a unified field but an array of convergent practices that explore a universe in which: a) print is no longer the exclusive or the normative medium in which knowledge is produced and/or disseminated; instead, print finds itself absorbed into new, multimedia configurations; and b) digital tools, techniques, and media have altered the production and dissemination of knowledge in the arts, human and social sciences. The Digital Humanities seeks to play an inaugural role with respect to a world in which, no longer the sole producers, stewards, and disseminators of knowledge or culture, universities are called upon to shape natively digital models of scholarly discourse for the newly emergent public spheres of the present era (the www, the blogosphere, digital libraries, etc.), to model excellence and innovation in these domains, and to facilitate the formation of networks of knowledge production, exchange, and dissemination that are, at once, global and local.
What I propose here in the Sente workflow for annotation really goes to the core of negotiating these convergent practices. While some utterly ill-conceived and poorly thoughtout news bites out there (like this piece in the New Republic) continute to herald the collapse of the humanities because no one supposedly reads books anymore in print (to be specific, the author somehow thinks that print qua paper is fundamentally different from print qua screen: “only wealthy institutions will be able to afford the luxury of faculty devoted to studying written and printed text…The change isn’t necessarily an evil to be decried but simply reflects how most people now generate and read narratives and text—they do it on digitally based multimedia platforms”), others trumpet the use of iPads and digital forms of print–and electronic annotation, as a fundamental revolution as if it has nothing to do with its analog counterpart, clearly missing the point. As expensive as iPads and iPhones may be, they are now “market center” and as popular as the newspaper used to be. I support a reasoned, populist approach to turning the idea of the exclusivity of the humanities (and contorted unsound evaluative categories of evaluating humanistic inquiry) on its head, come on folks!
The other problem is that there is a legitimate claim in the digital humantnies that in these convergent practices print and print like articles no longer constitute the only form of scholarship. Many contemporary professional scholars are not exclusively generating the ‘linear’ outputs–in other words, many people in academia are now producing unprintable digital scholarship. (Though for me, any idea will have to be communicable and sharable in some sort of linguistic way that resembles print, gasp!– language–at some point, or else consists of a (hermetic) futurism/avant-garde). The question is how does this kind of workflow change or work with this reality of new forms of scholarship? The question is well put because if non-printable scholarship is the real trajectory of the Digital Humanities, it could be argued that print-enabling energies should be spent on a more minimalist-coding based workflow approach that–I wager–will also help prepare scholars for more coding and data driven forms of scholarship that diverge from the written page.

The more coding-based adherents of DH support this excellent technology stack called Sustainable Authorship in Plain Text Using Pandoc and Markdown which is solid combination of already-made graphic interfaces, script libraries and coding for the creation of “linear” print and print-like forms. This approach’s most “consumer” component would be Zotero, which it combines with Pandoc and Markdown. But simplicity is its key appeal (it is an app, a package and coding)–though it is strikingly scholastic (and terminal-text based) and may feel for the outsider and like learning Latin. Its adherents believe the learning for it is extremely efficient, and that its open and interoperable approach is equatable to the learning curves associated with a stack of apps with higher pay off at the end. My point is that in many ways this coding based approach to the DH is almost as “hot” as the analog practices that preceded it, and that annotation gets to the heart of where “convergent” practices can not only intersect but combine a Sustainable Authorship in Plaintext Approach with great applications and graphical interfaces for different functions and processes (also on amazing interactive devices like iPads and iPhones). I hope that you will see by the end of this article that there is a great advantage to extending and hybridizing this sort of stack within a Sente workflow and seeing how a Plaintext-Pandoc-Markdown (MultiMarkdown approach) can evolve within a WYSIWYG consumer tablet-smartphone-laptop setting, in this case involving a fairly normative, but powerful and serious platform that allows non-coders the ability to do serious work: reaching a market of coders, pre-coders, non-coders, professional and amateur scholars across the spectrum of possibility.  The note-taking and later OPML-Plaintext hybrid workflow I propose here also does allow users to break free from apps that black box their work because the data is ultimately fungible as text (no data islands–provided one has understanding of how the file formats and processes work together), while on the other hand allowing one to move between and in and out of good, professional applications such as Sente, Scrivener, and DEVONthink which thus additionally allow intelligent users a great deal more power and flexibility–a dynamism which only increases exponentially when combined with the more coding based Markdown-Pandoc workflow. Scrivener and DEVONthink now offer full support for Markdown and MultiMarkdown and one can easily migrate plaintext fruitfully between these various applications.
The note-taking and later OPML-Plaintext hybrid workflow I propose here also does allow users to break free from apps that black box their work because the data is ultimately fungible as text (no data islands–provided one has understanding of how the file formats and processes work together), while on the other hand allowing one to move between and in and out of good, professional applications such as Sente, Scrivener, and DEVONthink which thus additionally allow intelligent users a great deal more power and flexibility–a dynamism which only increases exponentially when combined with the more coding based Markdown-Pandoc workflow. Scrivener and DEVONthink now offer full support for Markdown and MultiMarkdown and one can easily migrate plaintext fruitfully between these various applications.
Analog Annotation and Reading

Now that we’ve established that bridging and evolving textual practices between the hot and cool media and practices is really an important function of the digital humanities, there is a great deal of value to figuring out how to do traditional annotations, like making marginal and keyword annotations in texts; to make them actually work out in the digital medium by thinking about how it has been done since time immemorial.
In fact, my feeling on this is that the convergence of digital tools and traditional practices actually improves the traditional organization and doing of research in the analog mode in many myriad ways. Let’s take this example, a page from Dante Alighieri’s Convivio that I have annotated for my dissertation, which exemplifies the highly personal and individual “hot” medium analog experience of textual scholarship and reading in terms of “annotating” and an old school version what we now call #tagging. It also exemplifies its limitations in comparison to what computers can do.

Having spent a lot of time with academics, this is more or less a classic example of how many scholars read books (some I know keep their annotations separate, but in that case would somewhat mirror their response to the text outside of it but still with it). What can we say about the defects of analog annotating?
- The analog annotations are locked in analog practices. When you make annotations directly on the pages, you have to have an external apparatus or filling system or cards, or index to your own highlights and quotes.
- The analog annotations are not searchable.
- Underlines are not actual records of quoted material. Underlines are ambiguous as to the meaning of the underlined text.
- The tags and keywords (keywords and words, as in my example, like “princes” are effectively tags) that go next to analog quotations are often times something you forget unless you immediately pair it with an explanation and commentary in a notecard or separate sheet of paper.
- There is little physical space for elongated commentary in marginal spaces which makes it really difficult to really comment there meaningfully whilst thinking and reading. Hence the popularity of speaking of “marginalized” literature as a metaphor for something sidelined next to a dominant and canonical text/authority. (Medievalists in the house: think scripture, Glossa Ordinaria, Corpus Iuris Canonici, Latin auctores, etc. etc.)
- If you have annotated a whole book, with marginal notes, underlined key quotes, and marginal keywords, some of which are cross-references, when you are working on a larger project, these analog annotations and cross-references are unable to speak to each other. Here we go to Ted Nelson’s Xanadu vision and Lehmann’s analog solution. Cross-referencing is literally like “See above p. whatever” cross referencing–hated because they are easy to break in publishing (when pagination gets off or material added or adapted)–but when we marginally annotate we hardly ever do this. Wikilinks and hyperlinks, or digital references would be great! This is why indexes were so important for evolved pre-digital print culture.
- When it’s intertextual, i.e. between ideas or facts or proper nouns in other works, authors or texts, if we wanted to make use of these marginal annotations, we’d really need to start manually re-hashing all of them and quickly assembling an outline before we forget why they are important, or what exactly the intertext is.
When this is migrated to the digital medium, it offers multiple improvements. The rest of this post will address how Sente and Sente assistant help us evolve all of this!
Annotations in Sente for Mac
I’ll demonstrate the annotations in the iOS Sente below, but let’s get started in the desktop Sente. If you’d like to see any of this in action, you can check out the official video on the website of Third Street Software or Dan LaSota’s Youtube video. To annotate a pdf attachment simply open the attachment by double clicking it in the library window. You can also access the attachment pane by clicking the reference and pressing command + option + G (⌘+ ⌥+ G). In the attachment pane, above the displayed PDF file, you will note two icons (below).  The “A” stands for text annotation, while the square frame allows you to take snapshot annotations (think about taking a snapshot picture of an image or portion of the PDF itself) by drawing the frame around the portion you wish to record. I’ll detail the snapshot function below. For now, let’s just examine the text annotation functions (this should be active by default): all you have to do is click and highlight the text, which will bring up the annotation panel selector.
The “A” stands for text annotation, while the square frame allows you to take snapshot annotations (think about taking a snapshot picture of an image or portion of the PDF itself) by drawing the frame around the portion you wish to record. I’ll detail the snapshot function below. For now, let’s just examine the text annotation functions (this should be active by default): all you have to do is click and highlight the text, which will bring up the annotation panel selector. 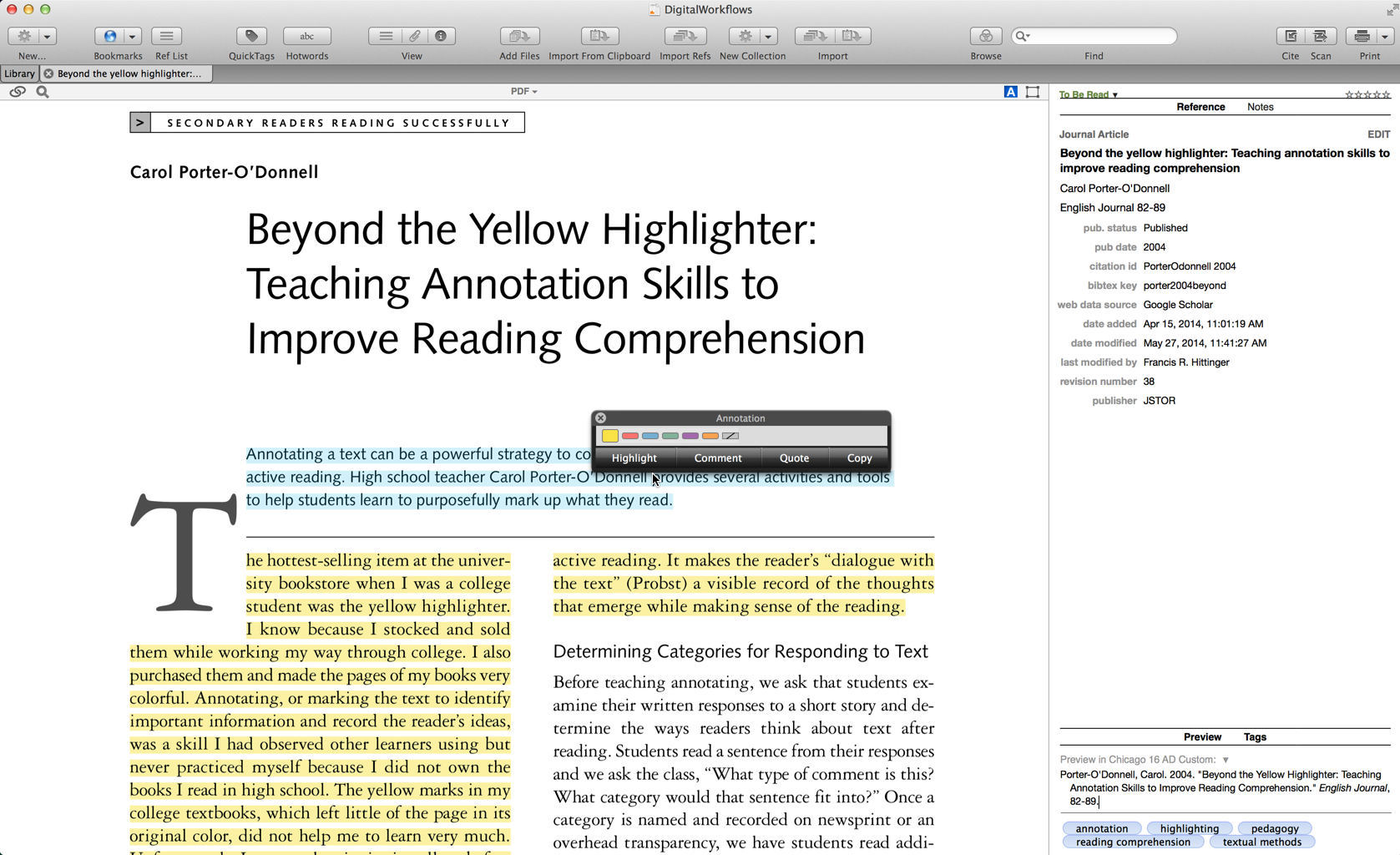 Tis the question, highlight, comment, or quote? Obviously you can copy if you want to put the quote on the clipboard immediately. I think highlighting and commenting can serve a function, but my preference is to use the “quote” function almost all the time. This is because the highlight function merely highlights the text (like underlining it is only of momentary cognitive-reading value, being active in reading or marking something is important) , and the comment function makes a blank note. This will be more apparent when you try it out.
Tis the question, highlight, comment, or quote? Obviously you can copy if you want to put the quote on the clipboard immediately. I think highlighting and commenting can serve a function, but my preference is to use the “quote” function almost all the time. This is because the highlight function merely highlights the text (like underlining it is only of momentary cognitive-reading value, being active in reading or marking something is important) , and the comment function makes a blank note. This will be more apparent when you try it out. ![]() Generally, though, the quote function is the best because as you are reading you can highlight salient quotes, you can select whatever color you’d like, and when you press the “quote” button, Sente will automatically snag the exact text into the notes panel, and add it to a running list of notes associated with the particular PDF in the reference. This is alas, the “notes” tab within the reference editor.
Generally, though, the quote function is the best because as you are reading you can highlight salient quotes, you can select whatever color you’d like, and when you press the “quote” button, Sente will automatically snag the exact text into the notes panel, and add it to a running list of notes associated with the particular PDF in the reference. This is alas, the “notes” tab within the reference editor.  In the example, pictured here (above), I’ve taken several annotations to exemplify this feature. A few things to “note”:
In the example, pictured here (above), I’ve taken several annotations to exemplify this feature. A few things to “note”:
- The default “quote” function will snag the selected text, highlight it on the PDF, and Sente, as circled above, will also place a sticky note icon (similar to Acrobat’s note icon) right next to your annotated text.
- Sente will generate the note title from the first sentence of the text you highlight. I highly recommend that you title your note based on a summary or key point of the cited text–this will serve you greatly later when you start exporting your notes for content outlines.
 The quoted text will appear under the title and a “comment” field will be left blank. Some people may want to simply quote the text and leave the comment field blank, others (and different people in different circumstances) will want to immediately comment. Below I’ll explain why I have so many phrases in $$tag$$ marks, but for now, the salient point is that I think it’s important to always put your comments in immediately. This function is great because traditional scholarship is reading and responding to ideas, and Sente’s quote/comment annotation function allows you to collect ideas and immediately capture your own responses.
The quoted text will appear under the title and a “comment” field will be left blank. Some people may want to simply quote the text and leave the comment field blank, others (and different people in different circumstances) will want to immediately comment. Below I’ll explain why I have so many phrases in $$tag$$ marks, but for now, the salient point is that I think it’s important to always put your comments in immediately. This function is great because traditional scholarship is reading and responding to ideas, and Sente’s quote/comment annotation function allows you to collect ideas and immediately capture your own responses.- Moreover, tying your comments to the reference and with the quoted text and page number–besides obviously assisting in the beauty of dialectical thinking–allows you to avoid the sin of plagiarism! In his post on Content Outlines, Daniel wrote about how important it is that an “information unit… be tagged with the source. This requirement is crucial to correctly refer to the source when you write the text. Otherwise you can (and likely will) be found out as plagiarist (give Google a few years more). And whether deliberate or not, that time-bomb will impede or even destroy your career.” Using Sente’s annotation feature to free associate and think with your quoted texts allows you to streamline and bridge your research and bibliographical practices and bridge them with your writing and poetic practices, while making sure you always remember where you had an idea and whose idea it is attributable to, and what page you found it on.
- As you see in the example, Sente will put the page number of the place where your quote is from in the PDF directly into the page number field in the note. This alone deserves a small discussion.
Page numbers–do it write!
I mentioned this in a previous post cursorily, and it has just come up again recently in the Sente forums: the issue of correct pagination. I participated extensively in that discussion already, so what I say here will be a brief distillation of that and I’ll leave it to you to think about. Depending on the PDF you are annotating, page 1 may very well be page xi of Latin front matter. Depending on the number of blank pages before the main text starts and the number of Roman Numeral pages of front matter (intro, preface, TOC etc.), likewise, page 20 of the PDF document could, in fact, be actual page 3 (or whatever) of the Arabic number pagination in the printed text of which the PDF is a facsimile. This divergence is a complicated part of the hybridization of textual scholarship between media and is very very difficult to automate software to read it correctly. The good news is that the newest version of iOS Sente has vastly improved automating it, but it’s still your responsibility to manually correct, if necessary. I suggest doing it first along with making the annotation. It would be hell to fix later.
Therefore: thou shalt always make sure when you add an annotation that the pagination matches the published official pagination and would withstand bibliographic scrutiny.
Sente does not always do it automatically–but does so much better than Zotero, for example. I say do it “write,” because the purpose of marking and saving quotations, especially those we have comments on, is imperative for effectively citing and remembering where you found your text and for avoiding plagiarism in future writing projects. If you don’t do it right the first time, you may end up with an embarrassing error later. This is a key piece of metadata–especially when you run cite and scan routines for formatting footnotes, citations, and bibliographies. If the page number is wrong (John Doe 2014@12) and it should actually be (John Doe 2014@xi), you will end up with an erroneous note.
Color coding?
Sente allows you to color your citations according to the standard panel of colors (below). I have mixed feelings about color coding. Drosophiliac has some thoughts about color coding in his post on An Academic Notetaking Workflow. I’ve tinkered with an adaptation of his ideas for color coding, below, but I think it will be more appealing to other people as I personally have tried this and decided that it was more distracting than helpful. I know some people are obsessed with color coding and will love this sort of scheme, and perhaps I’ll try it out again sometime.
- Red – Summary
- Orange – Important Methodological or Theoretical Information
- Yellow – Key Information (historical/factual/topical)
- Green – References (to other background info, papers, specific citations to follow up on)
- Cyan – Hypotheses and interpretations
- Magenta – Intertexts, connections to other texts, conntections to my own projects/ideas, questions for further research
You can choose whatever you want, but should probably stick to the deafault color palette above and consistently retain labels.
Snapshot and Image Annotations
In Sente, you can also take “snapshot” annotations. This is especially helpful if you want to capture an image or or a table or figure in a PDF, for example, that does not at all translate into OCR, and is hence not really annotatable based on the document’s OCR information. 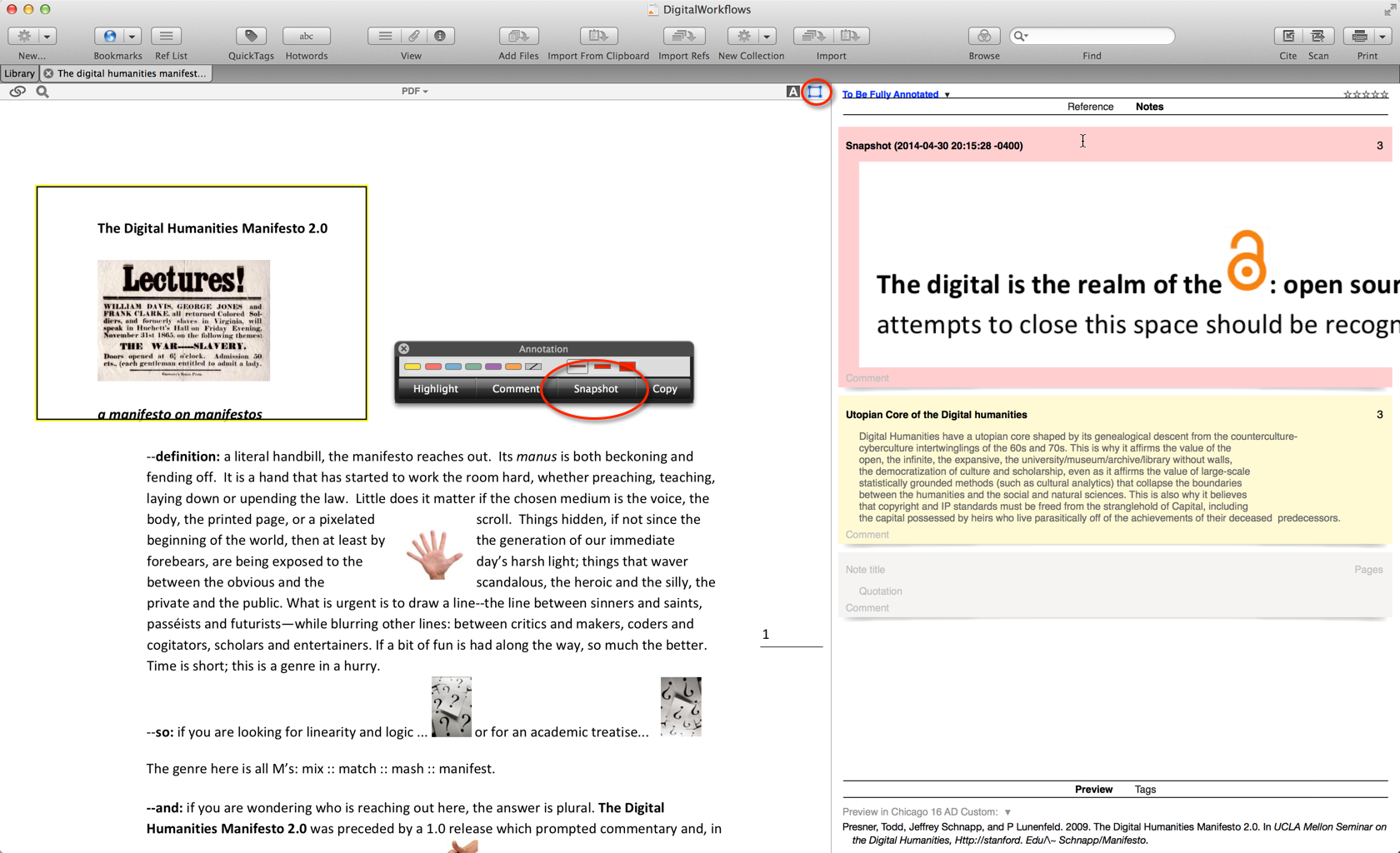 For example, say you want to note and comment on an Image, or simply want to use it later and remix it. Just click the Square box in the annotation panel. Draw a box around the object, and click “Snapshot.”
For example, say you want to note and comment on an Image, or simply want to use it later and remix it. Just click the Square box in the annotation panel. Draw a box around the object, and click “Snapshot.”  The “snapshot” now appears as an individual note in the notes pane. There’s nothing more to it.
The “snapshot” now appears as an individual note in the notes pane. There’s nothing more to it.
Sente for iPad and iPhone: Setup and Interface 
The exciting news is that while writing this post I had the opportunity to beta test the new version of Sente, which has now been expanded to work on iOS generally–to put it on your iPhone and/or iPad– get it in the App Store. Here I will quickly walk you through the features, which should be familiar to you from what I’ve already said about desktop Sente. Generally, the new Sente iOS interface offers seamless synchronization and functionality with your synchronized libraries. I tend to read just as much on my iPhone as I do on my iPad, and I’m just thrilled that everything now syncs on my phone too. (In fact, there’s something of a phone device zombie-ism around, we are all walking around constantly glued to our devices, especially iPhones and Androids. Perhaps the addiction to devices is not a good thing, but I’ll leave you to be the judge of that). First things first. When you install a library, it will download from your cloud account. 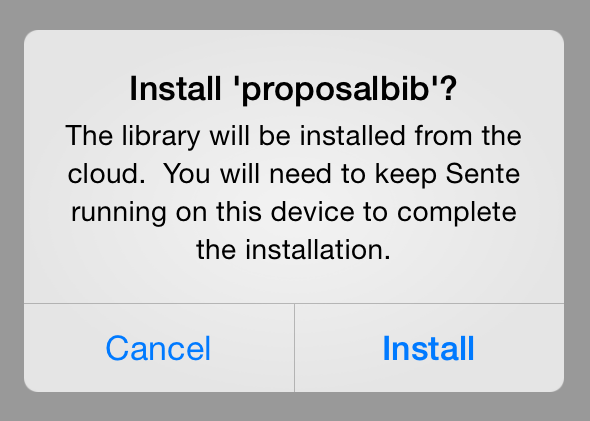 The next box will ask you to decided to download all or download attachments ad hoc:
The next box will ask you to decided to download all or download attachments ad hoc: 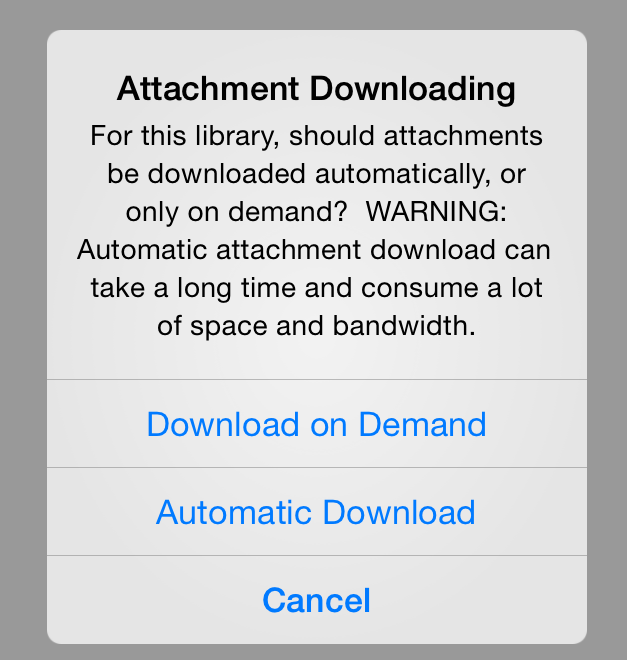 What you choose here should really depend on how big your iPad storage is. I invested in a 128gb capacity iPad, so I could automatically download all my attachments, but on my iPhone, which is limited to 16gb, I do download on demand, also because I have data service on the iPhone, but not on the iPad. The Sente Library screen will now pop up and your references will be installed from the cloud.
What you choose here should really depend on how big your iPad storage is. I invested in a 128gb capacity iPad, so I could automatically download all my attachments, but on my iPhone, which is limited to 16gb, I do download on demand, also because I have data service on the iPhone, but not on the iPad. The Sente Library screen will now pop up and your references will be installed from the cloud. 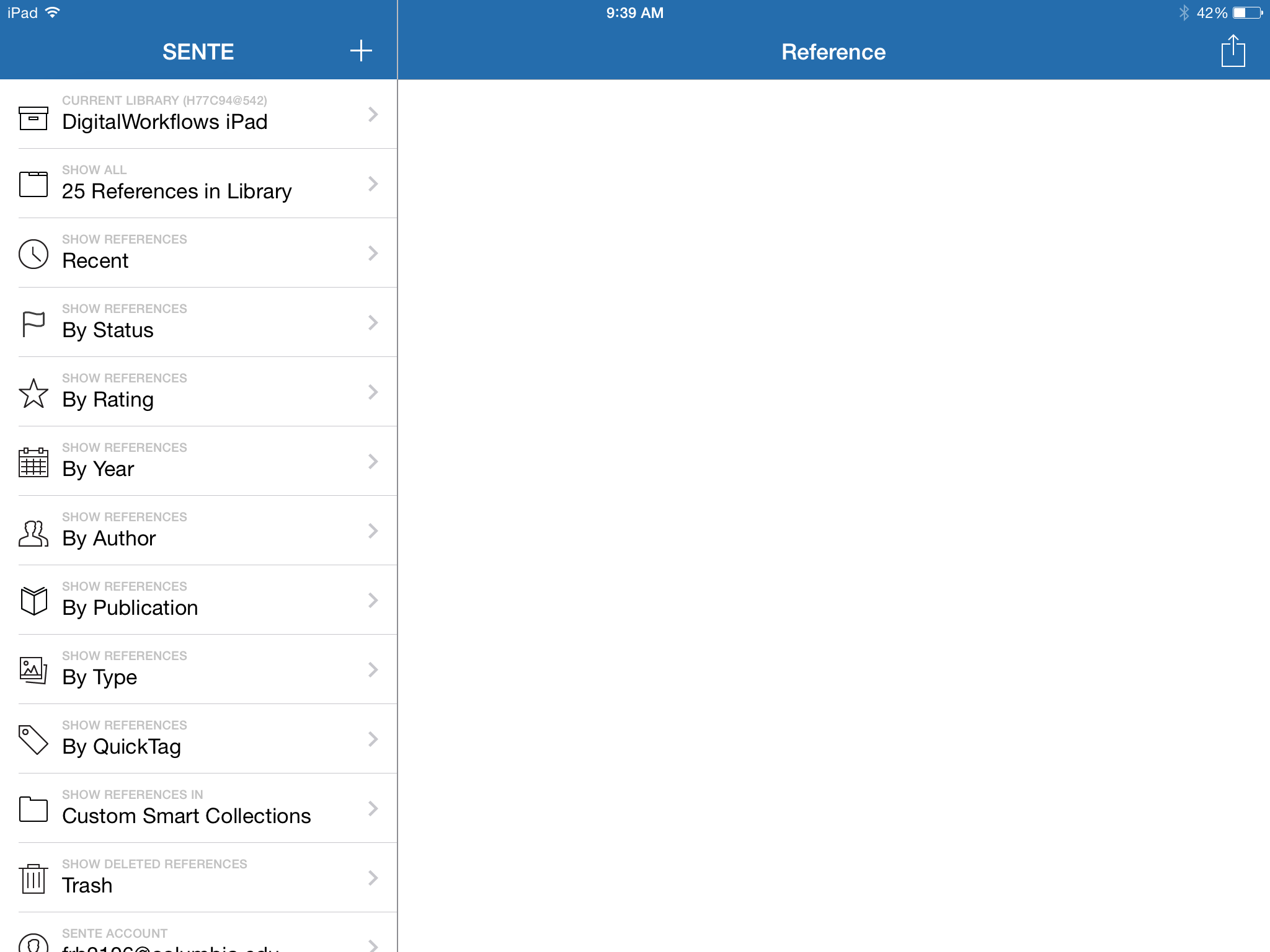 I won’t try to explicate this because I have already gone over the functions, such as Smart Collections, Ratings, Status etc. in the previous posts. It should just be noted that you can navigate your library that way as well as via your Quick Tag ontologies from the Desktop Sente in the iOS version too once everything has synchronized. Once your references have synchronized (and if you chose automatic sync with a very large library, you may need to give it some good time to sync), you can access your references by Pressing on the file folder icon –here “25 References in Library”– and it will open the list.
I won’t try to explicate this because I have already gone over the functions, such as Smart Collections, Ratings, Status etc. in the previous posts. It should just be noted that you can navigate your library that way as well as via your Quick Tag ontologies from the Desktop Sente in the iOS version too once everything has synchronized. Once your references have synchronized (and if you chose automatic sync with a very large library, you may need to give it some good time to sync), you can access your references by Pressing on the file folder icon –here “25 References in Library”– and it will open the list.
iOS Sente: Downloading Attachments
If you’ve chosen not to download automatically, you need to press the triangle button on your reference, or navigate to the “File” tab and select to download the reference from the cloud sync.  iOS Sente: Reference Pane
iOS Sente: Reference Pane
Here I will show you reference editor interface first, and later the reading and annotation interface. By way of example here is a reference with an attachment I read and annotated for this post. I’ve downloaded the attachment, so let’s get started by familiarizing ourselves with the reference pane. 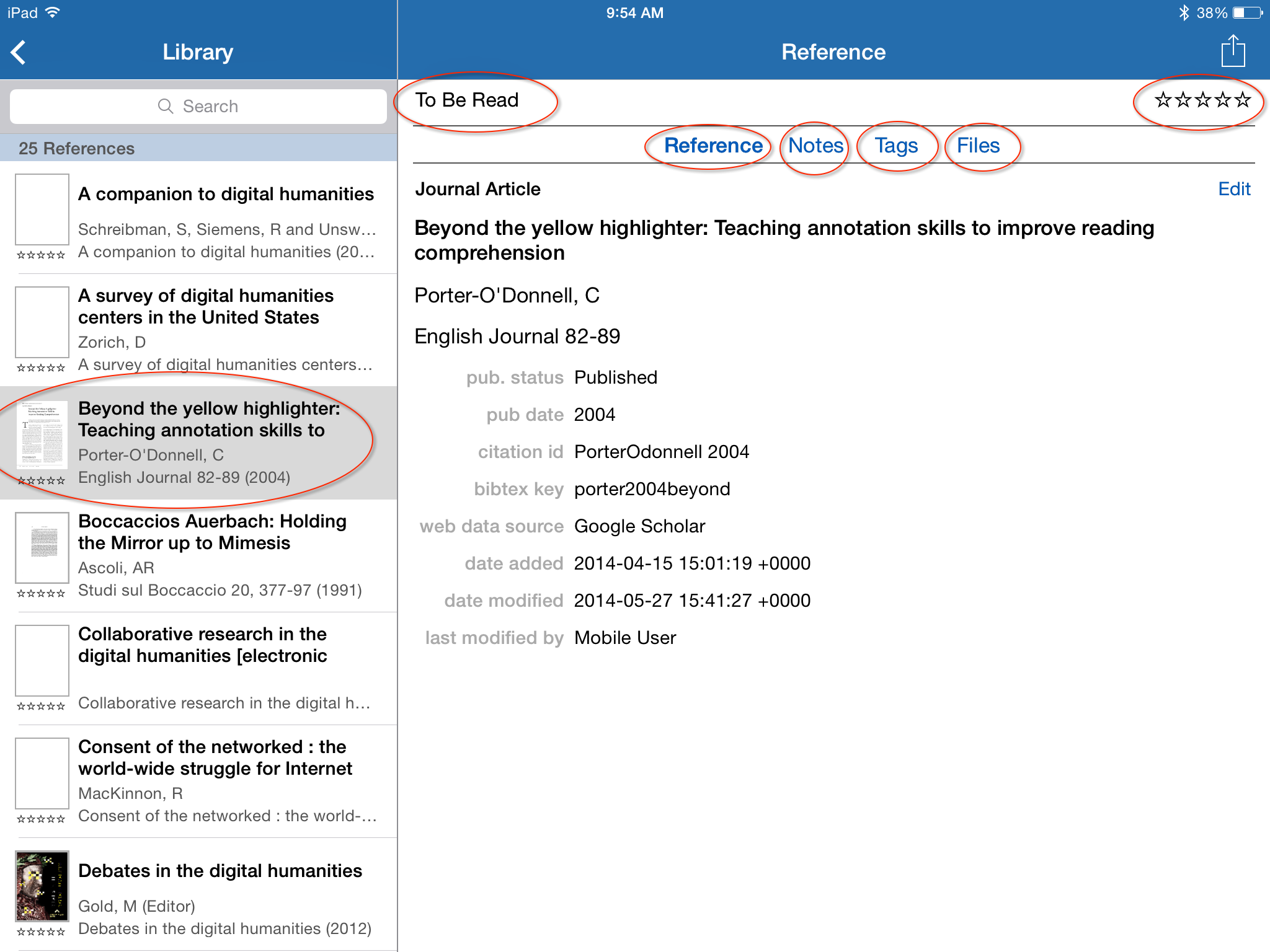 There are four menus you can access here. “Reference” is the initial window, and is basically the iOS equivalent of the reference editor in the desktop version. Pressing “edit” will allow you to modify and correct the metadata of your reference, as usual. Likewise, you see that whatever statuses you setup in your library have synced here too, and you can also assign a rating. Pressing “Tags” will allow you to add or modify tags to your reference.
There are four menus you can access here. “Reference” is the initial window, and is basically the iOS equivalent of the reference editor in the desktop version. Pressing “edit” will allow you to modify and correct the metadata of your reference, as usual. Likewise, you see that whatever statuses you setup in your library have synced here too, and you can also assign a rating. Pressing “Tags” will allow you to add or modify tags to your reference. 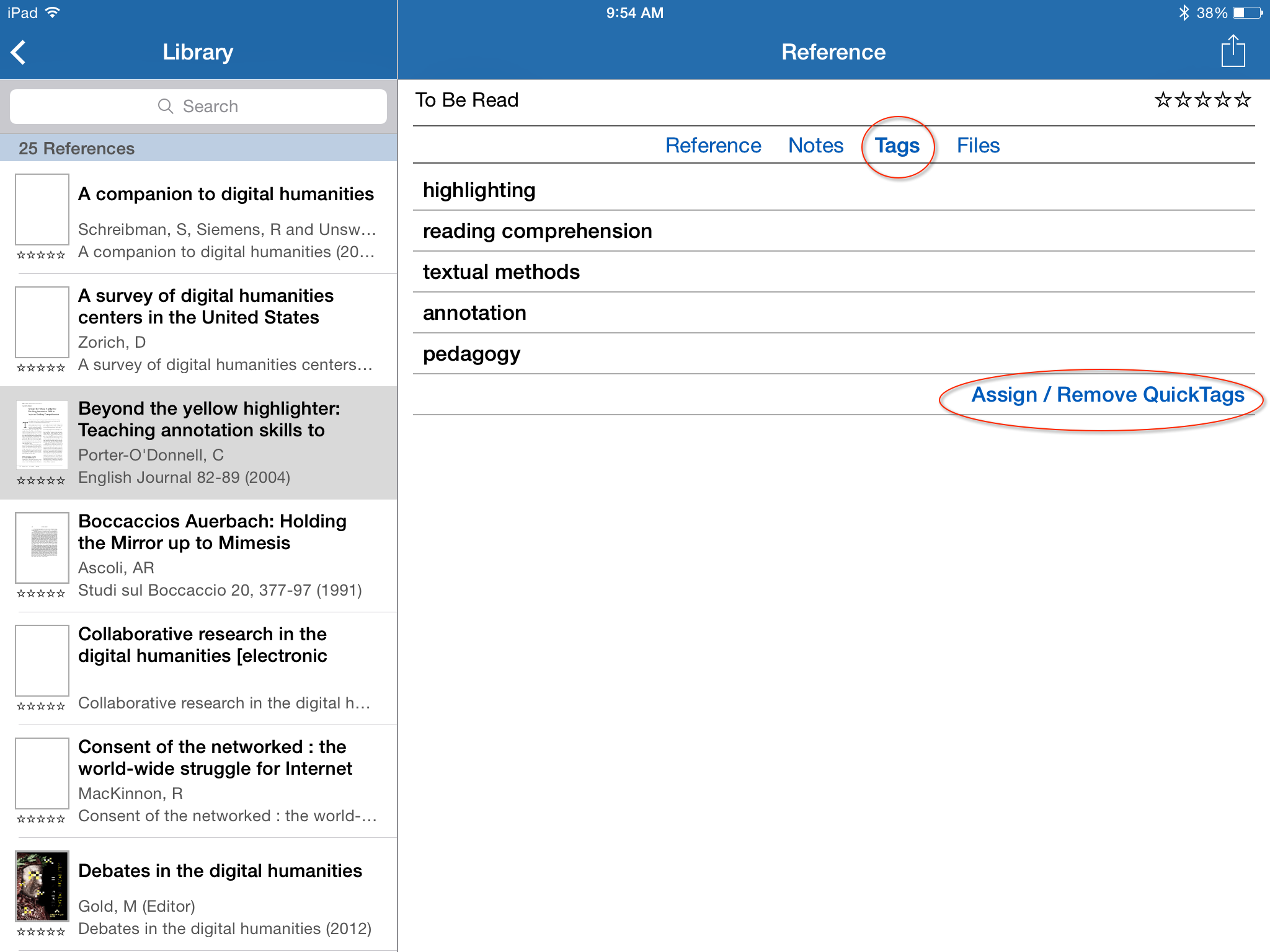 Pressing the “File” menu will display the auto link options for the reference,
Pressing the “File” menu will display the auto link options for the reference,  Here, for example, clicking the “Google Scholar” Autolink, will open the iOS Sente browser (for the record, I won’t discuss it here but you can also do target browsing and file downloading in the iOS Sente browser in a way that is similar to the desktop version). Here we see the “Google Scholar” page of similar articles. Clicking on any of the entries will allow you to enter targeted browsing mode and save new references and PDFs.
Here, for example, clicking the “Google Scholar” Autolink, will open the iOS Sente browser (for the record, I won’t discuss it here but you can also do target browsing and file downloading in the iOS Sente browser in a way that is similar to the desktop version). Here we see the “Google Scholar” page of similar articles. Clicking on any of the entries will allow you to enter targeted browsing mode and save new references and PDFs.  In any case, as I was saying before, besides the auto links, you can also open the attachment from within the reference pane: pressing “open file” will open the PDF in Sente’s reading interface.
In any case, as I was saying before, besides the auto links, you can also open the attachment from within the reference pane: pressing “open file” will open the PDF in Sente’s reading interface.  You can also access the reading interface of an attachment by pressing on the icon of the PDF in the library pane, provided it’s already been downloaded. As you see, I’ve already annotated this some, but how does the digital annotation and reading work?
You can also access the reading interface of an attachment by pressing on the icon of the PDF in the library pane, provided it’s already been downloaded. As you see, I’ve already annotated this some, but how does the digital annotation and reading work?
Sente for iPad and iPhone: Reading and Annotation
Once we tap the PDF attachment, we enter the reading mode on the iPad–which will be intuitive for almost everyone who has used a tablet at this point. You will see thumbnail previews of specific pages on the bottom of the screen. To move ahead within the document you can tap forward pages on the thumbnails, or swipe from right to left with your fingers to move between pages like turing pages of a book. Moreover, the orientation will change on the iPad and iPhone depending on whether your are holding the device vertically or horizontally. You can also zoom in a quite crisp resolution to specific sides or parts of the PDF within the Sente reader depending on what’s comfortable for your own eyes. So reading down the page I find a quote I’d like to remember. iOS Sente makes this a piece of cake.  Using either a stylus of choice, or my finger, I simply highlight the text i’d like (dragging the two selector dots around the text) and the annotation menu comes up. It includes the same options that the desktop version does. In this case the quote actually wraps into the next column (this is not a problem on other non-column set PDFS) setting, so to capture the whole sentence or paragraph I copy the rest of the portion on the next column first, then press quote on the selected text and go back in and am ready to paste it in my reference.
Using either a stylus of choice, or my finger, I simply highlight the text i’d like (dragging the two selector dots around the text) and the annotation menu comes up. It includes the same options that the desktop version does. In this case the quote actually wraps into the next column (this is not a problem on other non-column set PDFS) setting, so to capture the whole sentence or paragraph I copy the rest of the portion on the next column first, then press quote on the selected text and go back in and am ready to paste it in my reference. 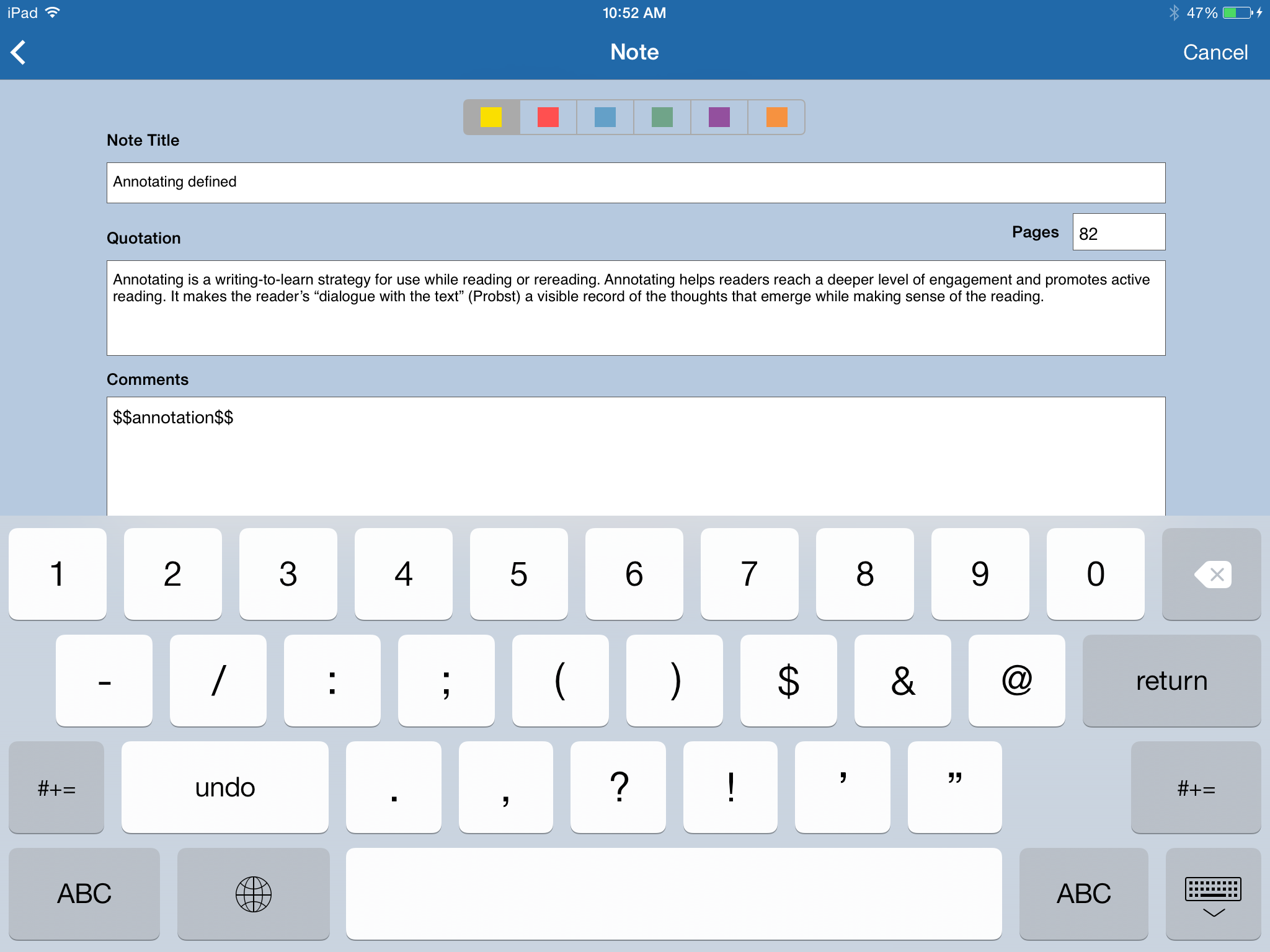 Note that the actual page 82 matches the page number printed in the digital text. You will always want to make sure the page numbers match. I discussed this already, and the new iOS version of Sente has made some great improvements in this arena, but as a good practice, as with all metadata, it is worth making sure it’s right the first time. Reading through the text I can zoom in close to the text easily, Sente puts a little icon next to my highlighted text, there is no pixelation:
Note that the actual page 82 matches the page number printed in the digital text. You will always want to make sure the page numbers match. I discussed this already, and the new iOS version of Sente has made some great improvements in this arena, but as a good practice, as with all metadata, it is worth making sure it’s right the first time. Reading through the text I can zoom in close to the text easily, Sente puts a little icon next to my highlighted text, there is no pixelation:  Here is what that annotation looks like in the annotation editor:
Here is what that annotation looks like in the annotation editor: 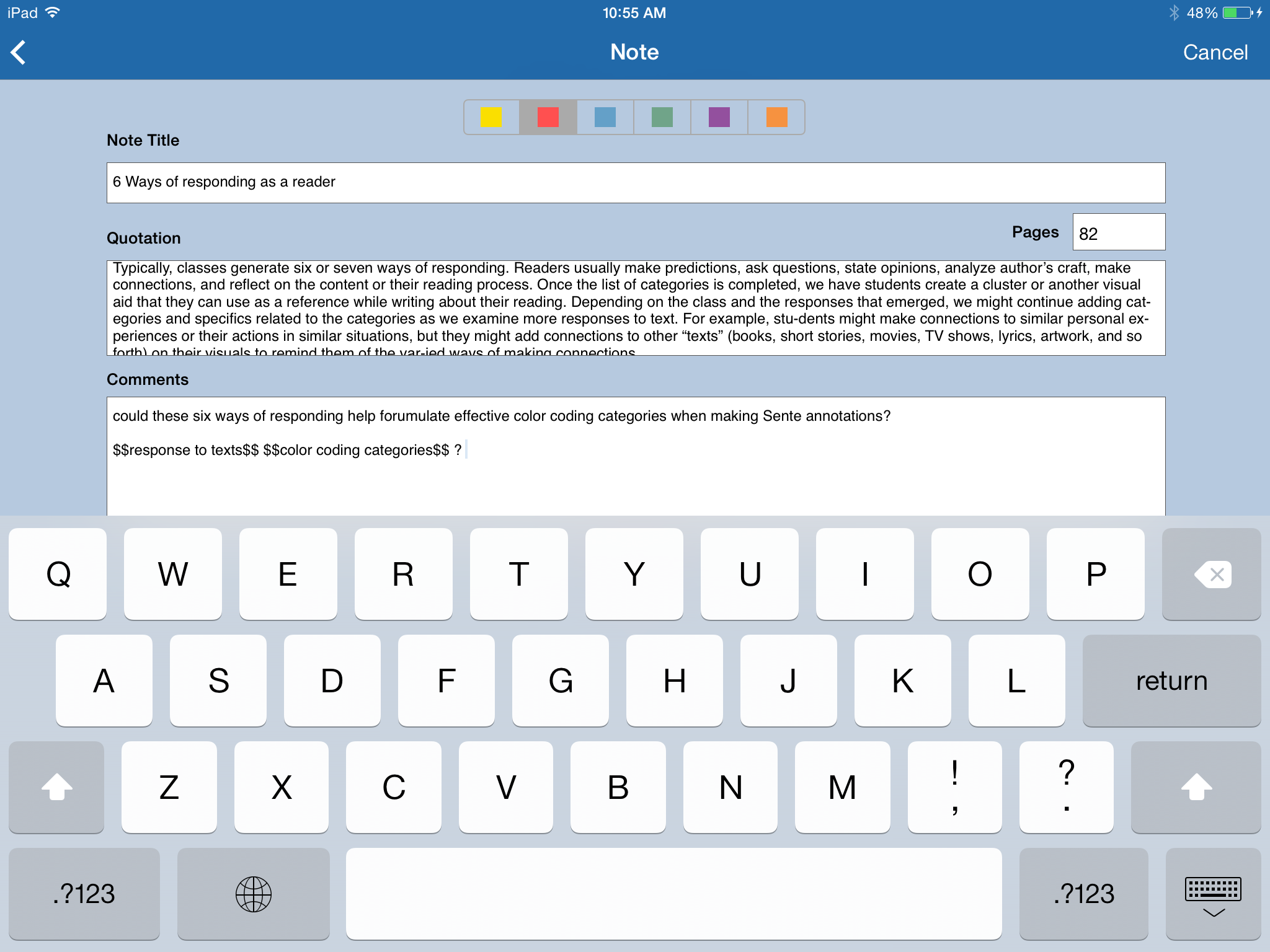 On the iPhone:
On the iPhone: Serious Sente annotators will want a durable bluetooth keyboard/case combo. I use this Belkin case keyboard combo with my iPad air. It’s about $100, but why not get the most of your iPad investment?
Serious Sente annotators will want a durable bluetooth keyboard/case combo. I use this Belkin case keyboard combo with my iPad air. It’s about $100, but why not get the most of your iPad investment?  I think having the keyboard option handy makes taking annotations on the train or bus a breeze. There are a myriad of styli out there, I don’t think it matters which one you pick, but I personally like one that feels like a real pen or pencil. The physical feedback or at least nostalgia for the traditional reading and writing practice feels really really good as an iPad (which inadvertently weights about as much as a slim scholarly hardback) digital humanist. There’s just something about holding the stylus and reading the text like an old book that I like, call it philology I guess.
I think having the keyboard option handy makes taking annotations on the train or bus a breeze. There are a myriad of styli out there, I don’t think it matters which one you pick, but I personally like one that feels like a real pen or pencil. The physical feedback or at least nostalgia for the traditional reading and writing practice feels really really good as an iPad (which inadvertently weights about as much as a slim scholarly hardback) digital humanist. There’s just something about holding the stylus and reading the text like an old book that I like, call it philology I guess.
Browsing Bookmarks and Annotations
Once I’ve annotated everything, I can browse my annotations and bookmarks. Click the Book icon at the top of the window in reading mode: 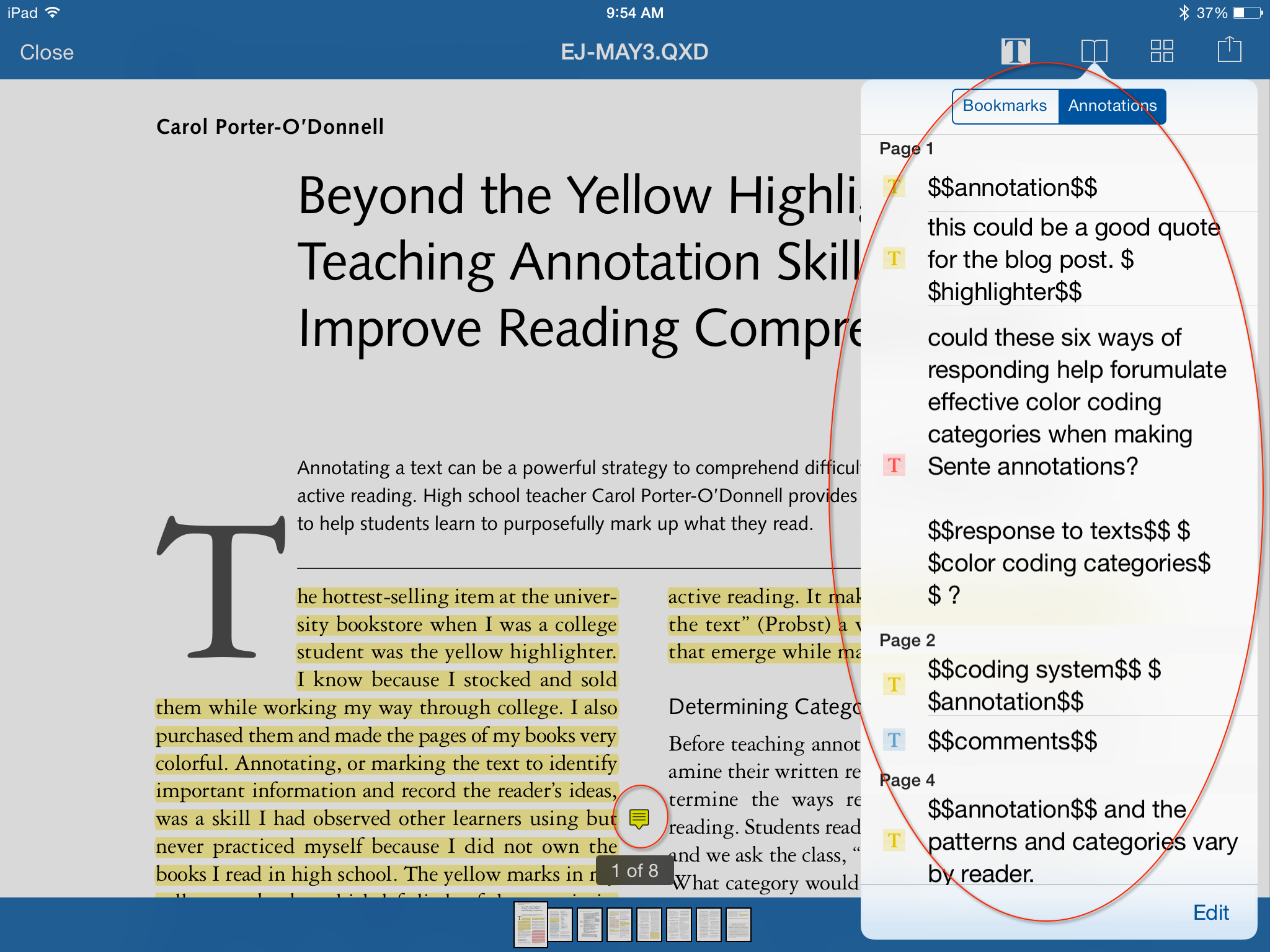 Here we can see the pages I’ve bookmarked. Press the plus button to add a new bookmark, and “edit” to edit them.
Here we can see the pages I’ve bookmarked. Press the plus button to add a new bookmark, and “edit” to edit them. 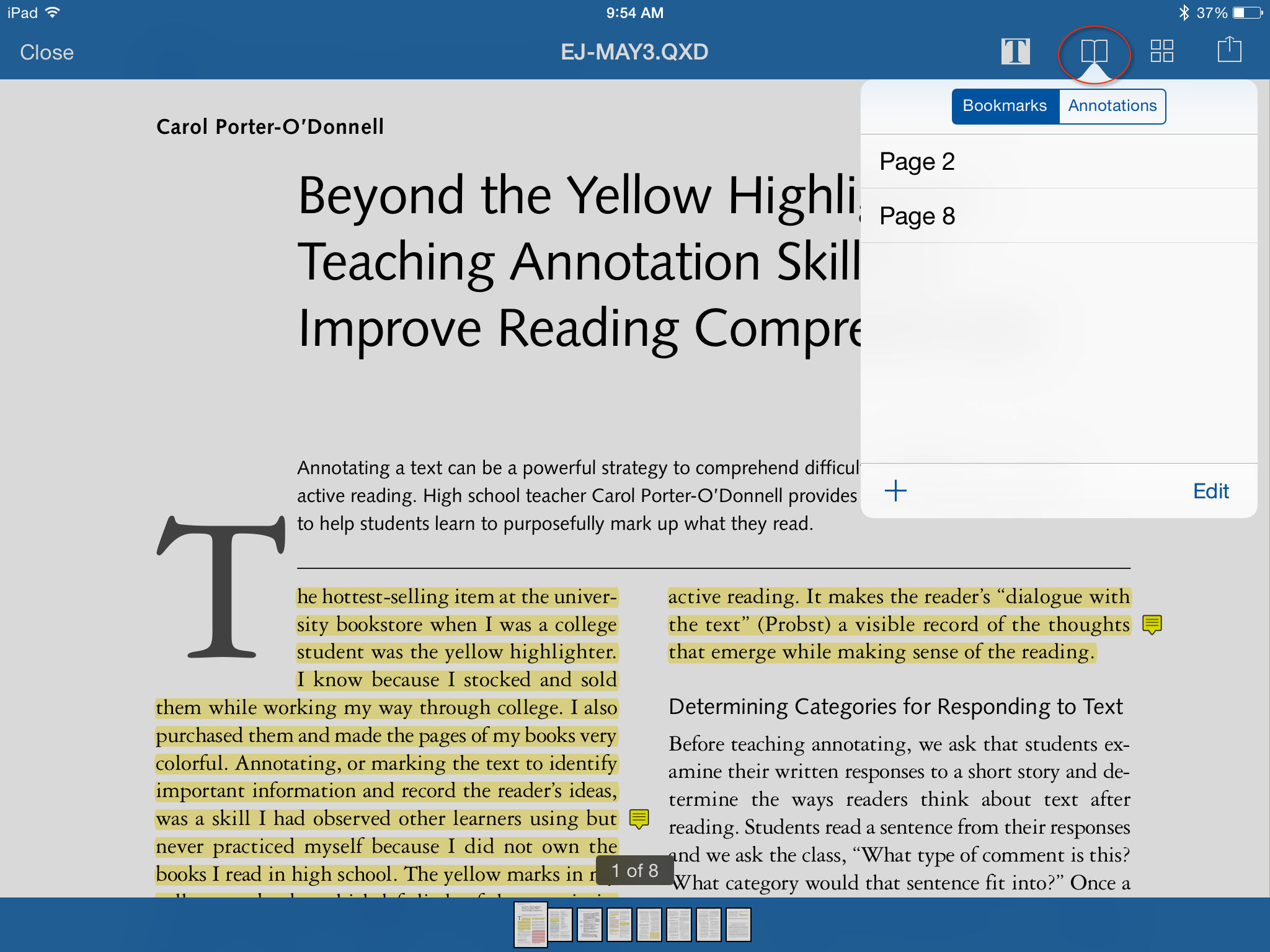 Going back to the reference pane, you can also view your notes and access them from the “notes” tab–and again–this time on my iPhone, not iPad. The joy, everything is synchronized!
Going back to the reference pane, you can also view your notes and access them from the “notes” tab–and again–this time on my iPhone, not iPad. The joy, everything is synchronized! 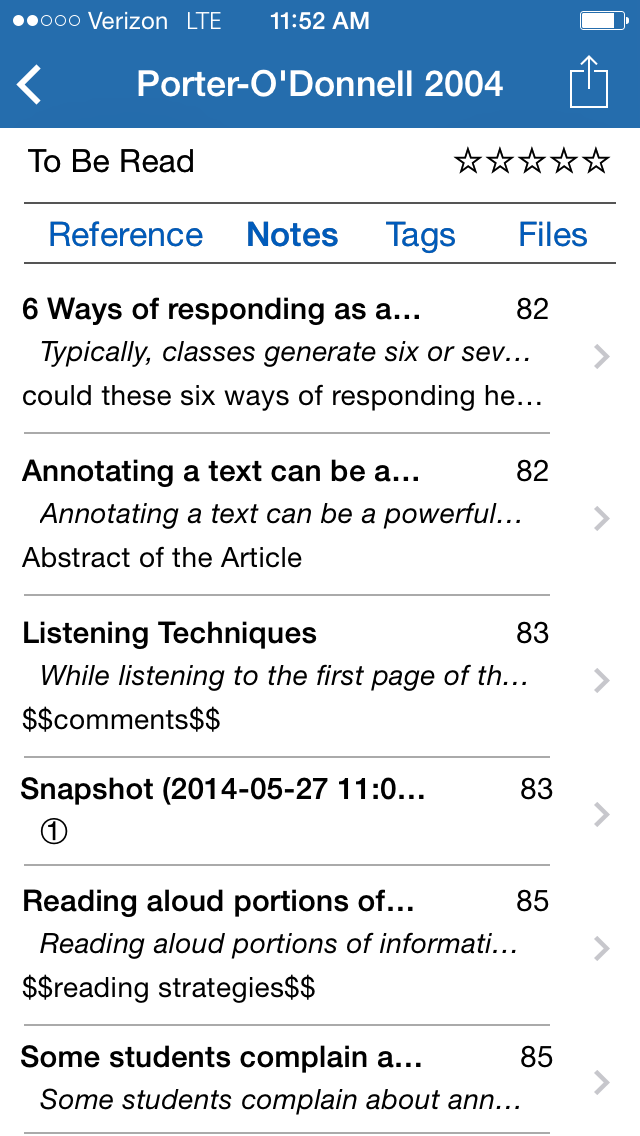 Otherwise, Sente’s iOS interface really allows you a lot of flexibility in browsing your documents, quotes, comments, annotations and highlights. You can view everything as a gallery of thumbnails.
Otherwise, Sente’s iOS interface really allows you a lot of flexibility in browsing your documents, quotes, comments, annotations and highlights. You can view everything as a gallery of thumbnails.  The Book icon will open a tab that contains tabs. The bookmarks and annotation tabs will take you back to your individual annotations or bookmarked pages embedded in the PDF through the Sente browser. But I like the outline tab as well because it translates and enhances the traditional table of contents function. If your PDF has the table of contents metadata built in Sente will allow you to navigate the document (book, really) by the outline TOC.
The Book icon will open a tab that contains tabs. The bookmarks and annotation tabs will take you back to your individual annotations or bookmarked pages embedded in the PDF through the Sente browser. But I like the outline tab as well because it translates and enhances the traditional table of contents function. If your PDF has the table of contents metadata built in Sente will allow you to navigate the document (book, really) by the outline TOC. 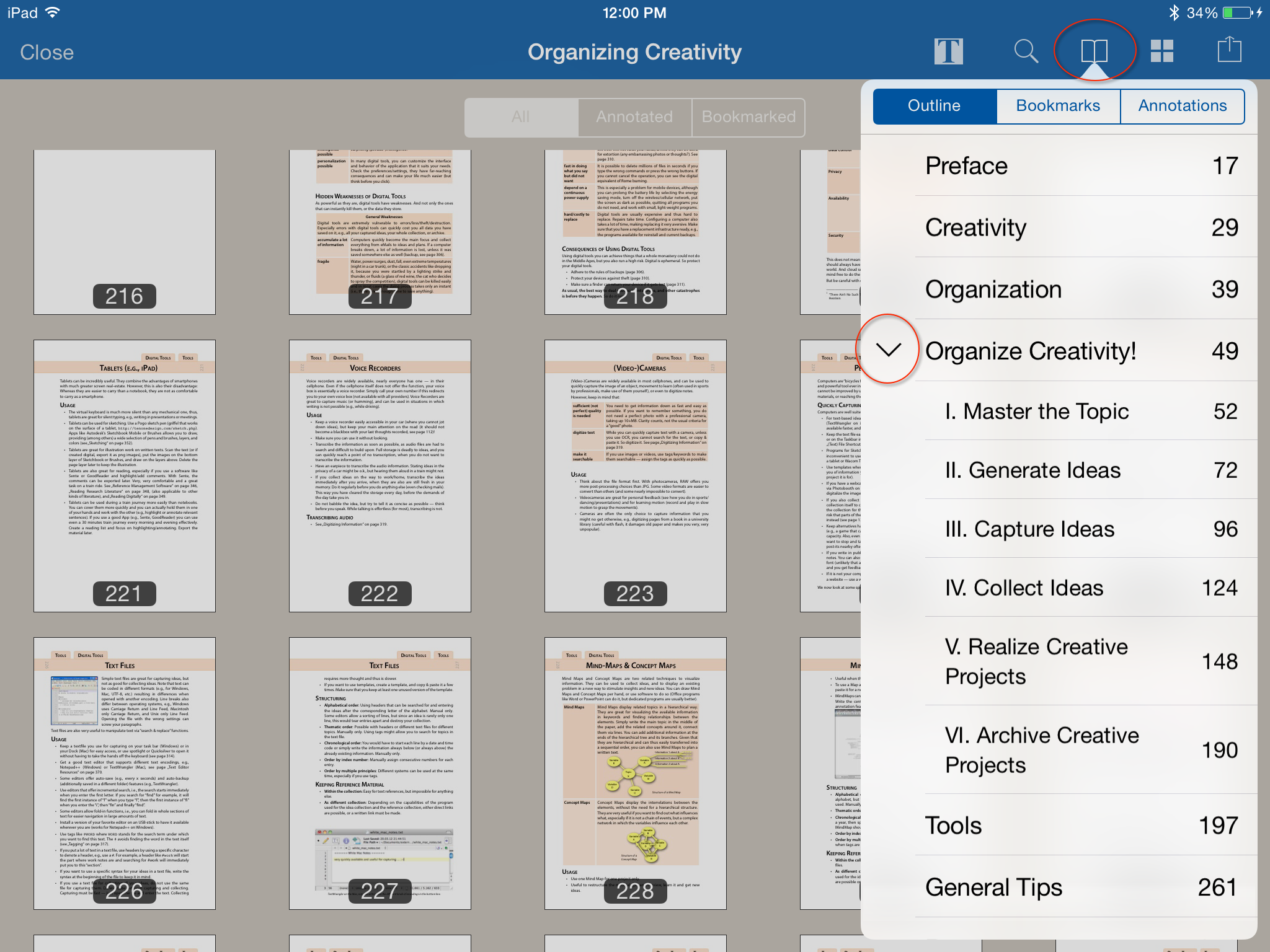
Searching in iOS Sente
Another great function is the OCR search functionality. The Search Icon, with magnifying glass was added in an update 6.81 after I took the above screen shots, but was really present the whole time as well in the previous version and in the initial 6.8 iOS release via the action menu (I only mention it to make sure there’s not confusion about why it was missing in some of the other screen shots). 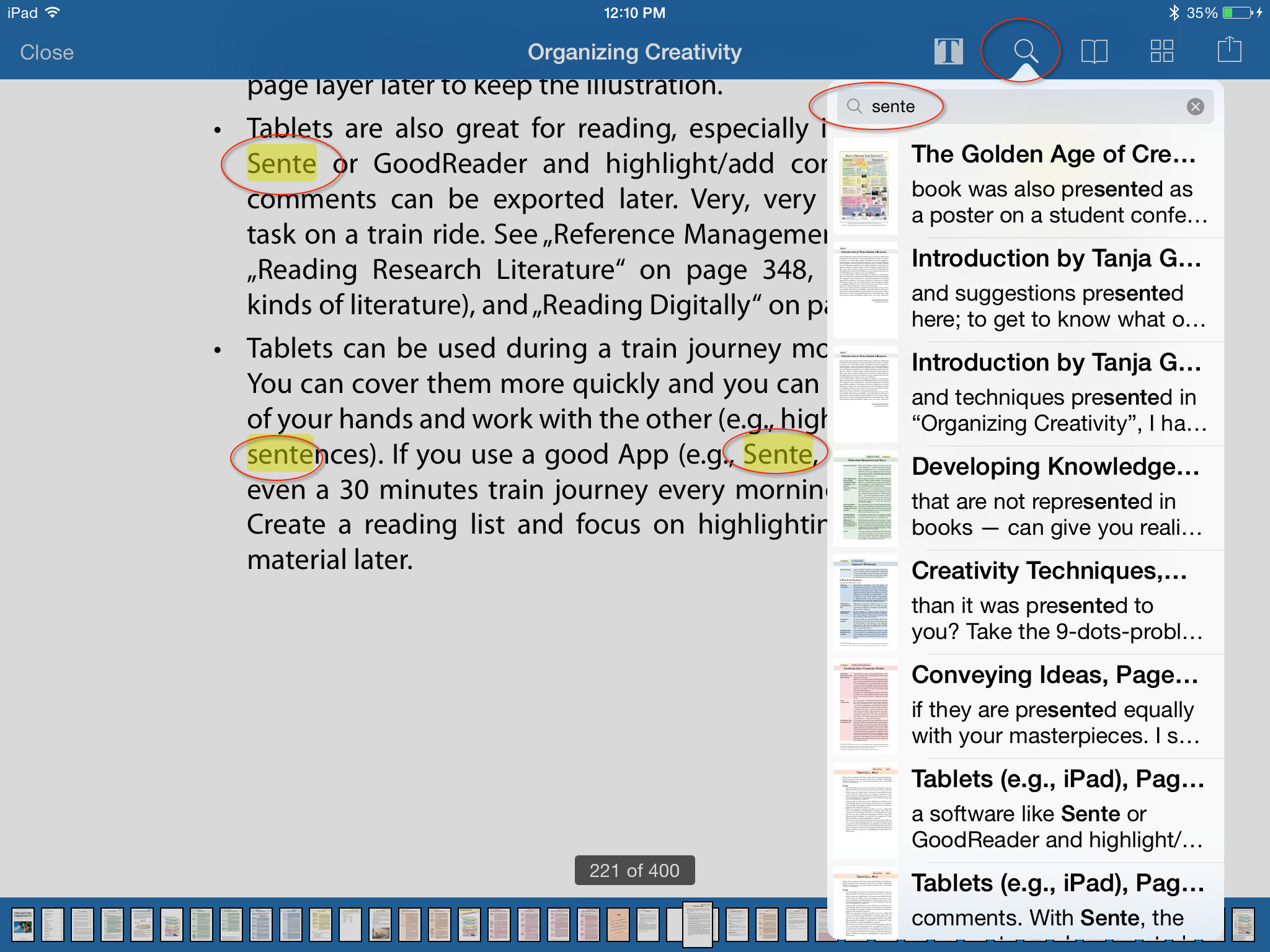 This function is really great and enhances the reading and note taking functionality of the traditional linear printed text when translated into OCR text and made fungible on the iPad device. You suddenly have something that works like an enhanced e-text. If you want, for example, to read and annotate based on certain keywords, or tag pages based on those keywords, bookmark based on key words, Sente’s got you covered here too. As you can see Sente will find all the instances of the search string, and allow you to navigate to the pages where it is found. It will also, as in the example (above) highlight them, in this case, the instances of “Sente” in Daniel Wessel’s book Organizing Creativity. Obviously, other PDF readers and software have this function too, but the complex of functions under one roof, here geared towards the nuts and bolts of academic research and reference management is the key and crowning part here, and the ability of searching the PDF for OCRed text that allows you to dynamically to create and manage your own archive of metadata that pairs with your own research database.
This function is really great and enhances the reading and note taking functionality of the traditional linear printed text when translated into OCR text and made fungible on the iPad device. You suddenly have something that works like an enhanced e-text. If you want, for example, to read and annotate based on certain keywords, or tag pages based on those keywords, bookmark based on key words, Sente’s got you covered here too. As you can see Sente will find all the instances of the search string, and allow you to navigate to the pages where it is found. It will also, as in the example (above) highlight them, in this case, the instances of “Sente” in Daniel Wessel’s book Organizing Creativity. Obviously, other PDF readers and software have this function too, but the complex of functions under one roof, here geared towards the nuts and bolts of academic research and reference management is the key and crowning part here, and the ability of searching the PDF for OCRed text that allows you to dynamically to create and manage your own archive of metadata that pairs with your own research database.
Emailing Notes and Attachments in iOS Sente
By this point you’re probably thinking “this is great, but how do I manage and organize all these individual citations?” You can enter your annotations in the reference pane and can always opt to send them to yourself. 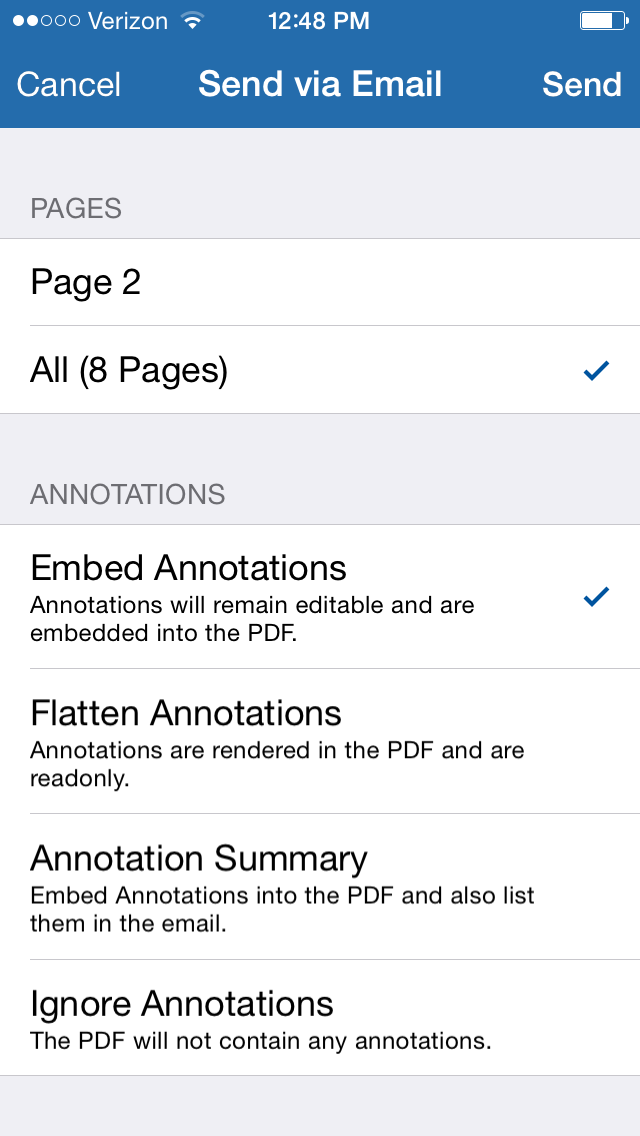 Once you make your choice, press send and Sente will automate the process and open a new email for your in apple mail.
Once you make your choice, press send and Sente will automate the process and open a new email for your in apple mail.
Power Note Taking with Sente Assistant
But what about making use of your many annotations as a personal archive? How to deploy them and find particular annotations? Since Sente still doesn’t yet allow you to tag individual notes, but only references, the Sente community has created it’s own solution to this. Many of you have by now noticed the many $$tagged$$ strings I put into my individual comments. I put them there as the digital equivalents of keyword or sticky tags or marginal key words in the margins of texts. This allows me, using the tag characters $$string string$$ along with Sente Assistant to start generating a tag index within my Sente library.  In my opinion, Sente Assistant is perhaps one of the crowning examples of what kinds of practical things can occur from a determined user group dedicated to finding solutions to creating more functionality in already great software. Sente assistant is an amazing commercial-free companion application to Sente written by M. Roberts and inspired by Dana Leighton’s script, which I will discuss in the post on OPML–where I will continue showing you other applications of how to move reference and note information out of Sente into other applications as part of a complete workflow. No doubt some of these features are things I’m sure Sente’s development team are going to natively include in future releases of the software, but for now, Sente Assistant’s features add significantly to the already amazing functionalities of the iOS and OS X Mavericks suite.
In my opinion, Sente Assistant is perhaps one of the crowning examples of what kinds of practical things can occur from a determined user group dedicated to finding solutions to creating more functionality in already great software. Sente assistant is an amazing commercial-free companion application to Sente written by M. Roberts and inspired by Dana Leighton’s script, which I will discuss in the post on OPML–where I will continue showing you other applications of how to move reference and note information out of Sente into other applications as part of a complete workflow. No doubt some of these features are things I’m sure Sente’s development team are going to natively include in future releases of the software, but for now, Sente Assistant’s features add significantly to the already amazing functionalities of the iOS and OS X Mavericks suite.
Running Sente Assistant on your synchronized Sente libraries, all your notes and references become instantly accessible as a personal archive. The Sente Assistant allows you to:
- Browse your Sente notes, sorted by their correct position on the source page
- Perform keyword, wildcard, or tag searches of your notes
- Search the references you select in Sente, or across all notes in your Library
- Generate an index of all tagged notes
- Identify duplicate references in your library
- Save your filtered notes or search results in a single RTF, HTML, PDF, ODT, DOC, DOCX, or TXT file
- Customize the presentation of your notes in the Assistant
Download Sente Assistant (the thread for the application is found here). The most recent version is .68, and can be downloaded here. Once you download the package, click to unzip it, and navigate to the folder. I recommend reading the entire “Read Me,” though I will repeat some of the things here. To install the Assistant, unzip the file and place the entire Sente Assistant folder inside your Applications folder. All the pieces needed by the Assistant are contained within this one folder. To use Sente Assistant drag it to your applications folder. 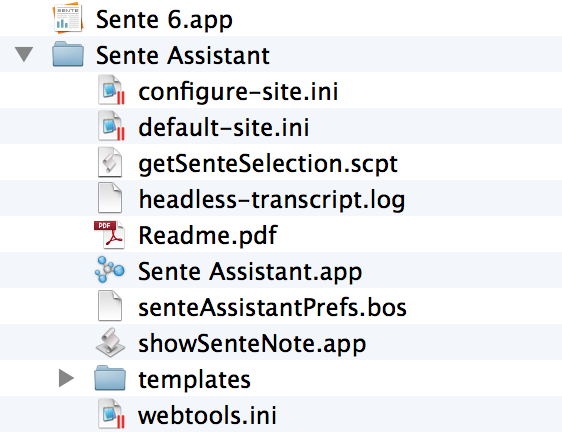 I’d also drag the Sente Assistant app into your dock bar, so you can easily click on it. Now, once that is done, you need to click the Icon “Sente Assistant”–which also is an application in the task manager called “Visual Works”, open Safari, and navigate to
I’d also drag the Sente Assistant app into your dock bar, so you can easily click on it. Now, once that is done, you need to click the Icon “Sente Assistant”–which also is an application in the task manager called “Visual Works”, open Safari, and navigate to
http://localhost:8008/senteAssistant.ssp
You will want to make a bookmark for this in your browser.
Sente Assistant Interface
Remember you have to have a Sente Library active. When your library is active Sente Assistant presents you several different options for visualizing your data. Notes and summary shows you the totality of your archive, in order of reference, as dialectic of your thoughts with other authors’ texts and intertexts.  You can also save all your notes into an RTF file.
You can also save all your notes into an RTF file. 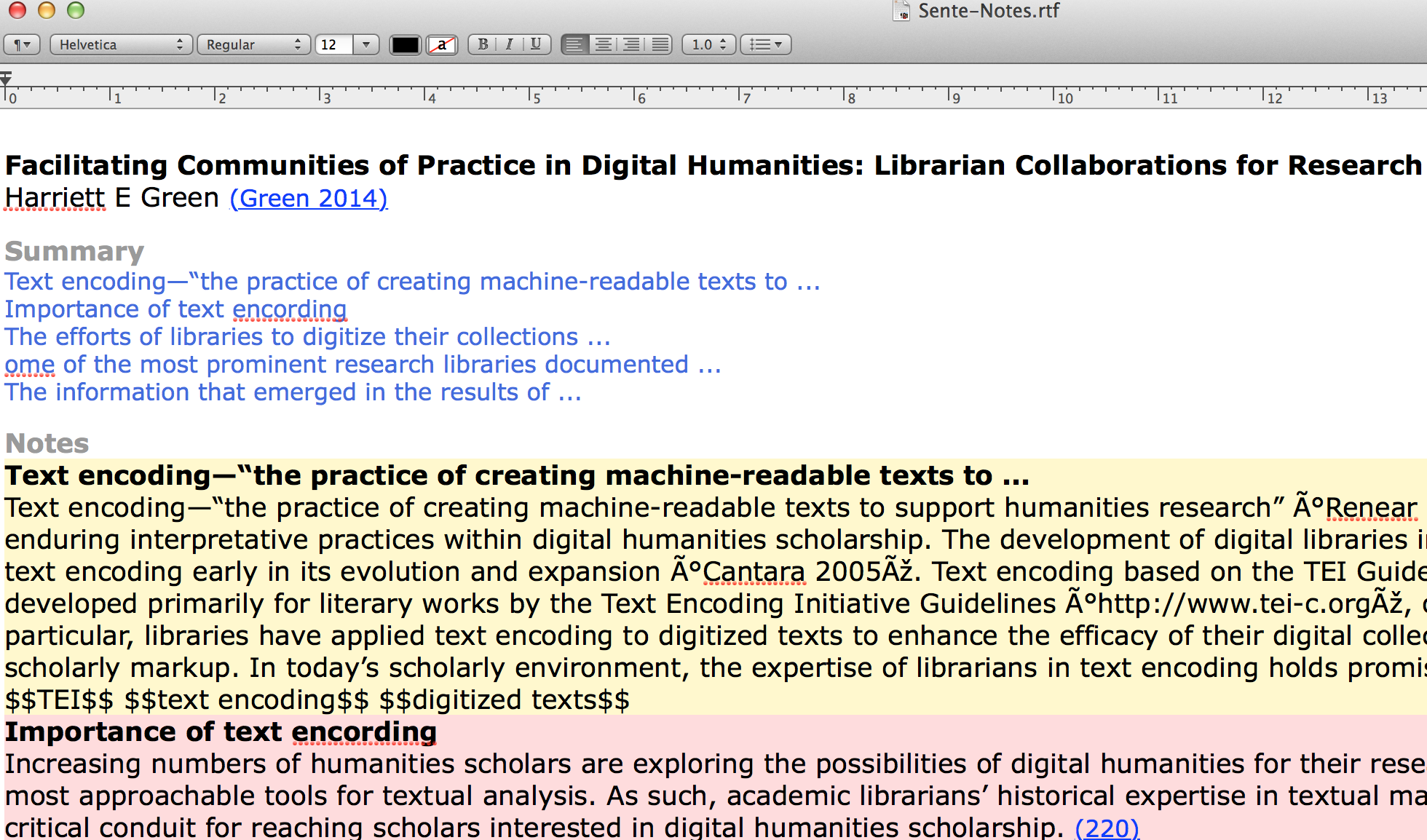 Tagging Individual Notes and the Sente Assistant Tag Cloud
Tagging Individual Notes and the Sente Assistant Tag Cloud
Sente Assistant’s preferences allow you to customize the color and textual aesthetics etc. as you’d like. Here the really important thing is how to configure your tags. I offer you something that I’ve experimented with and that think works well for several purposes. 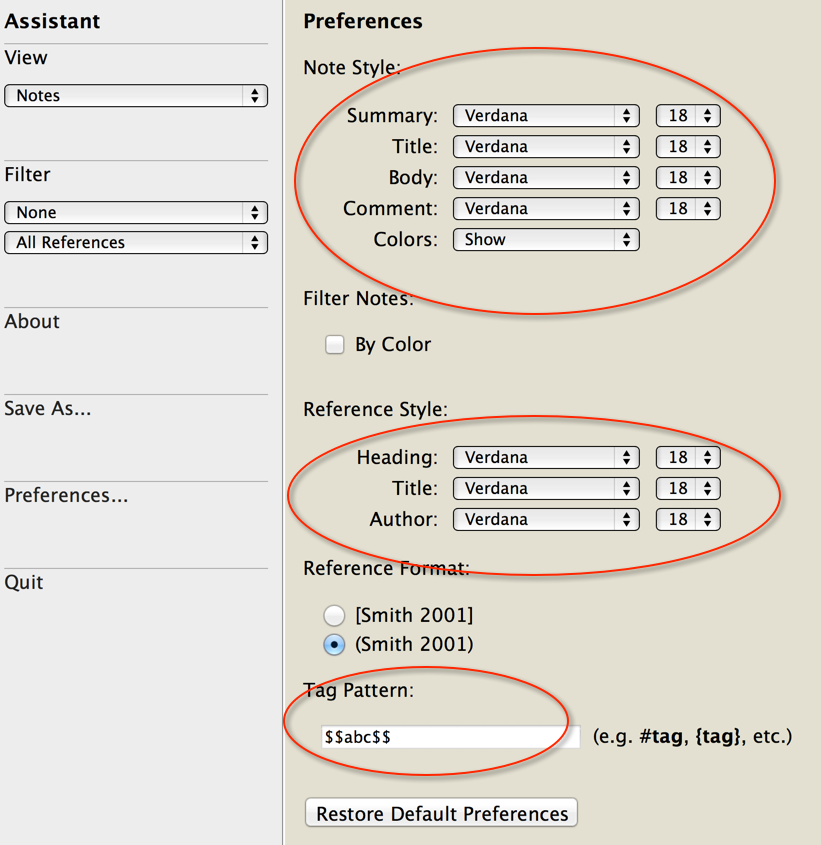 By default, the tag format uses a hash mark (e.g., #Sente), but you can make your own custom format from the “Preferences” pane. The tag pattern you set on this page is used to generate the tag index. If you use the hash mark or another single character, your tags cannot include spaces; however, if you use curly brackets or some other characters at the beginning and ending of the tag pattern, your tags can be strings that include spaces, hyphens, or other non-alphanumeric characters. For the tag markers, only non-alphanumeric characters are recognized for tags, with the exception of a few reserved characters used by the SQLite database (e.g., single quote, underscrore, percent sign, and ampersand). To save this configuration make sure Sente is closed, and then “quit” Sente Assistant. When you quit and re-open, you have to restart Safari and the Visual Works application (this is documented in the Sente Assistant) PDF manual. Thus the point is that using the familiar #hashtag we are all familiar with from Twitter, it is possible to tag individual notes, but I’ve tested several combinations, and I find the most reliable tagging regime here is to use $$tag tag$$ because it lets you make both one word and multiword tags that do not interfere with other characters in the system or SQLite database, and these tags do not interfere with plain text syntax that might be useful to those who routinely use Markdown and Multimarkdown to write. The result of these $$tags$$ in my notes can be seenin the list view, when you go to Sente Assistant’s “Tag Index”–accessible from a drop box menu in the interface.
By default, the tag format uses a hash mark (e.g., #Sente), but you can make your own custom format from the “Preferences” pane. The tag pattern you set on this page is used to generate the tag index. If you use the hash mark or another single character, your tags cannot include spaces; however, if you use curly brackets or some other characters at the beginning and ending of the tag pattern, your tags can be strings that include spaces, hyphens, or other non-alphanumeric characters. For the tag markers, only non-alphanumeric characters are recognized for tags, with the exception of a few reserved characters used by the SQLite database (e.g., single quote, underscrore, percent sign, and ampersand). To save this configuration make sure Sente is closed, and then “quit” Sente Assistant. When you quit and re-open, you have to restart Safari and the Visual Works application (this is documented in the Sente Assistant) PDF manual. Thus the point is that using the familiar #hashtag we are all familiar with from Twitter, it is possible to tag individual notes, but I’ve tested several combinations, and I find the most reliable tagging regime here is to use $$tag tag$$ because it lets you make both one word and multiword tags that do not interfere with other characters in the system or SQLite database, and these tags do not interfere with plain text syntax that might be useful to those who routinely use Markdown and Multimarkdown to write. The result of these $$tags$$ in my notes can be seenin the list view, when you go to Sente Assistant’s “Tag Index”–accessible from a drop box menu in the interface.  The plain text $$tags$$ are all indexed and hyperlinked now:
The plain text $$tags$$ are all indexed and hyperlinked now: 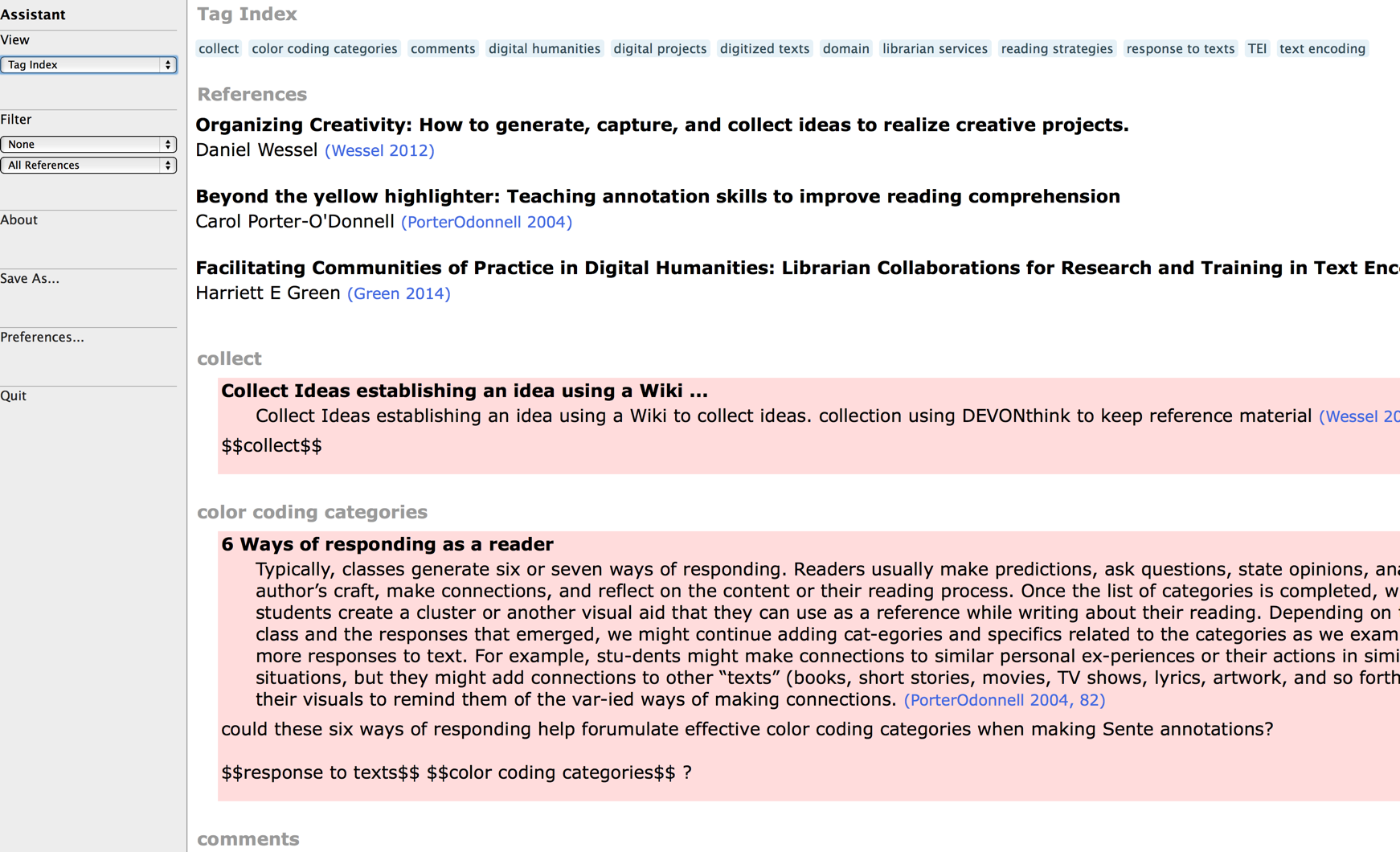 When you click on the tags within the assistant, it will take you to all the references which include the tag in that library (also keep in mind since it’s plain text embedded within the reference) you can move these across libraries and keep the tags. Sente Assistant will always interpret them.
When you click on the tags within the assistant, it will take you to all the references which include the tag in that library (also keep in mind since it’s plain text embedded within the reference) you can move these across libraries and keep the tags. Sente Assistant will always interpret them.
In the next section I talk about using Markdown and Multimarkdown in notes, but $$tagging$$ with dollar signs in my Sente annotations translates into beautiful tag clouds. If you employed this over hundreds or even thousands of your own comments and notes in your Sente reference and annotation database, the sky would be the limit for harnessing the power of your personal thought archive. There are ways this can be amplified using a Wiki or DEVONthink that cannot be discussed here fully, but Sente Assistant allows this tagging, tag clouding and searching not just of all notes, but of individual notes.
This is something different for now from the Ulysses III kind of tagging using Openmeta tags, see Macademic on this, and I think that ultimately if you get DEVONthink in the mix you are all set in searching metadata. Anyway, I like this kind of tagging because it combines the best of WYSIWYG interfacing, plain text scholarship stacks, and the enhancements of digital text and tablet computing.
Idea: MultiMarkdown inside individual annotations
For those of you who use MultiMarkdown, you will probably like where I’m going with this. If you’re not familiar with MultiMarkdown, it is a derivative of Markdown and facilities easy formatting for writing hassle-free with plain text. Here’s a syntax guide for the uninitiated. The custom tags feature is great because whether you want to write in an outliner, mind map, or word processor, but desire to retain non-interference with other syntaxes, like MultiMarkdown, you could use your tag custom option and make dollar sign $$abc$$ for the tags to insert in the annotations to quoted passages.
This is great because that wouldn’t interfere with either with normal (John Done 2014@page number(s)) in texts–important for Citation Keys used in Cite-Scan functions (to be discussed perhaps in a different setting) or other identifiers with brackets in exported notes that I end up using in a body paragraph. Here’s an example I made in MultiMarkdown Composer: 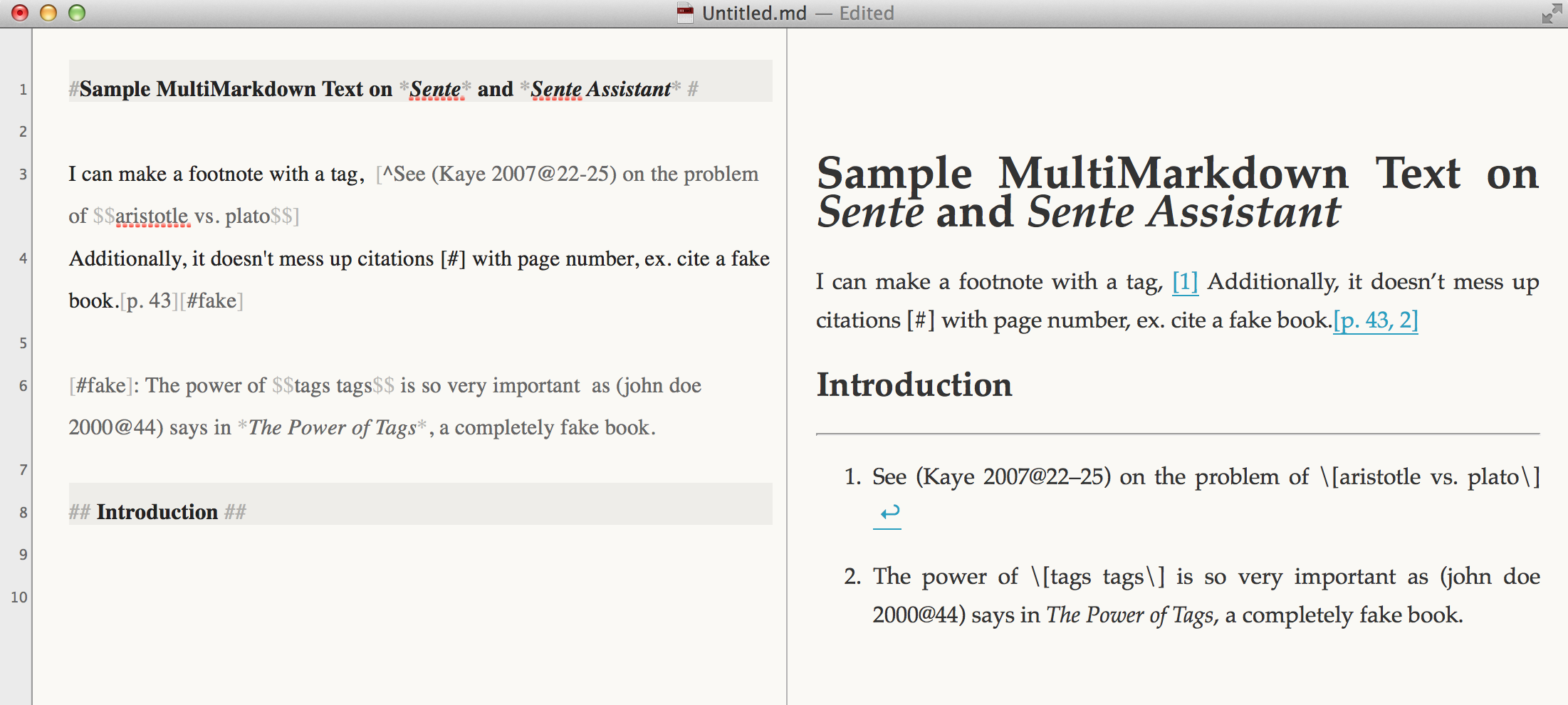 So if you’re not familiar with MultiMarkdown, to summarize: if I have a note with several tags in the comments, like $$tag one$$ $$economics$$ $$aristotle$$ $$food$$, and I export the notes into a text I’m writing –and they inadvertently end up in the editor or I keep them in a note or comment to remind myself of topics etc. in the tags as mental cue of whatever I want– I don’t have to worry about interference with (Author Year@ pages) citation tags from Sente, the “# “used by MultiMarkdown for headings, or even the other bracketed [^abc xyc cdefg] syntax for footnotes. In the end (as in the above example) you can annotate directly when doing the commentary on the text if you wish something like [^See (Kaye 2007@22-25)], which generates a footnote with the scan citation i’ve chosen. It doesn’t mess up citations [#] with page number, ex. cite a fake book.[p. 43][#fake] [#fake]: (john doe 2000@44)- etc. The tags, moreover, are rendered by MM like this: \[ tag \[.
So if you’re not familiar with MultiMarkdown, to summarize: if I have a note with several tags in the comments, like $$tag one$$ $$economics$$ $$aristotle$$ $$food$$, and I export the notes into a text I’m writing –and they inadvertently end up in the editor or I keep them in a note or comment to remind myself of topics etc. in the tags as mental cue of whatever I want– I don’t have to worry about interference with (Author Year@ pages) citation tags from Sente, the “# “used by MultiMarkdown for headings, or even the other bracketed [^abc xyc cdefg] syntax for footnotes. In the end (as in the above example) you can annotate directly when doing the commentary on the text if you wish something like [^See (Kaye 2007@22-25)], which generates a footnote with the scan citation i’ve chosen. It doesn’t mess up citations [#] with page number, ex. cite a fake book.[p. 43][#fake] [#fake]: (john doe 2000@44)- etc. The tags, moreover, are rendered by MM like this: \[ tag \[.
Some people might not like this, but you can easily delete the junk when you edit your paper, or simply find replace and delete all of them when ready, and at the least it will be a reminder to you that you had tagged a key piece of information there and perhaps you should make sure you don’t need to consult the tag cloud for more information there anyway. At the moment, these tags do not coincide with Openmeta tags, but if you put them into DEVONthink they should be indexed anyway.
Help, I need to take notes on a real print book!

Get a scan Pen! I personally use an older model IRISPen express 6, but have also become familiar with a newer generation Product called WorldPenScan, Made by PenPower Inc. I have not tested it, but I have used the IRISPen Express 6, and it works for me in English, Italian, and German with about 90% accuracy–meaning that if you learn to calibrate and use it correctly, as well as hold it well and not scan two lines of text you can get pretty good accuracy of OCRing text on the fly. In any case, the point is that you can and will want to scan quotes into your Sente library sometimes without having to physically scan the book and there’s no reason why you can’t do it into a blank note in Sente–this will also sync into your library.
Doing so is self-explanatory. Get a scan pen, scan the paragraph or lines:  In this example, I scanned a few lines from MacKinnon’s book, which needs a bit of manual correcting. Also, don’t forget to put in the proper page number, so that you don’t improperly cite it, if you end up doing so.
In this example, I scanned a few lines from MacKinnon’s book, which needs a bit of manual correcting. Also, don’t forget to put in the proper page number, so that you don’t improperly cite it, if you end up doing so. 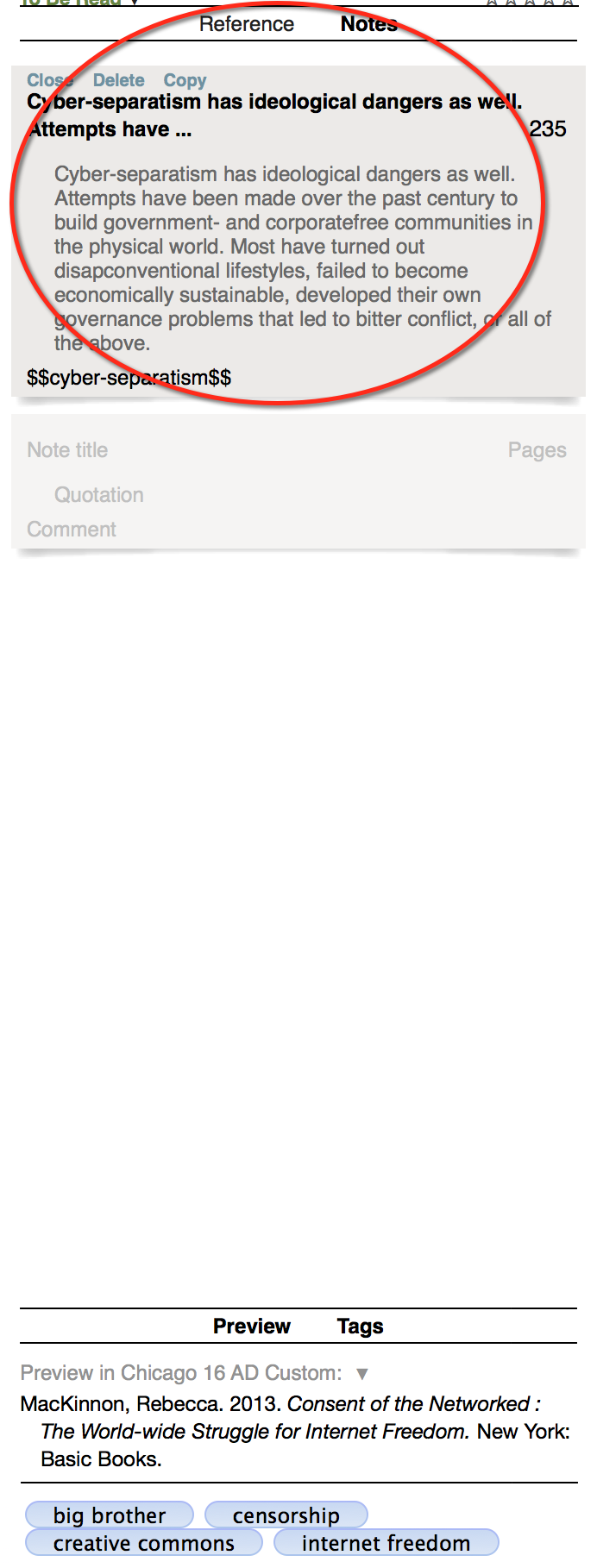
Francis,
Can’t thank you enough for going through your workflow and raising all of the issues related to doing digital research and note taking. I have spent the day following through your past posts and relearning how to get the most from Sente. I look forward to your future write-ups on integrating Sente, Devonthink, and Scrivener.
Thanks again.
I completely agree — an amazing resource. I’m directing my students and colleagues to this blog. I too look forward to the Devinthink post.