Greetings! Digital Center friends,
My name is Nanjun Lu, I come from China and now pursuing a Master’s degree in Electric Engineering at Columbia University. Unlike most of EE, CE or CS students who have keen interests in software development or hardware design, my primary research interests are power systems analysis, electric vehicle modeling and smart grid optimization. However, in the era of information, no matter which subjects or concentrations you are studying or pursuing, you can’t avoid dealing with a huge number of data. That’s how advanced technologies typically burgeon, grow and become influential.
In our daily life, social networks, company/school homepage and Google search take up most of our time using Internet, no matter you are social butterflies, Chemical experts or computer geeks, you can always find it’s easy to search and locate whether an article, a person’s profile or a restaurant location through online search engines in milliseconds, and that really changed our life today. While we are fascinated by how powerful and intelligent the websites are, the huge database in the back is the state of art technology that controls all of this. Because the database is what makes the network keep running in right track and the source of information, how to develop, manage and update the database are of great importance to nearly all kinds of websites.
Working as a Digital Center Internship at Digital Social Science Center is a great opportunity for me learn more about how to deal with data, solve the problems and even manage a database. And I’m very glad to have Ashley and Jeremiah as my supervisors. I started my internship last week and my first project is to set up the workflow for transforming the Lehman Library social work’s information from an Agency Catalog into a database. Under the guidance of Ashley, I developed the procedures of processing raw pages of cards into rows of information, which we can later insert into a database.
#Step 1 Scanning the pages into files, pdf, jpg or tif, etc with good qualities.

#Step 2 Chopping the scanned pages into individual cards through any software with high efficiency. Here, I chose Photoshop.




#Step 3 Cleaning up the speckles on the cards to ensure the higher readability for the reading software. Here, I used Kirtas BSE 1.9, which can not only enhance the quality of images, but also apply the same work to the rest in consistent manner.


#Step 4 Now, we are prepared to have the cards read by software and transform them into changeable texts for further corrections. In this step, ABBYY FineReader is applied to ensure the high quality of output.

Once the card images are converted into texts, we can insert the information into a database. Our next step is to build a database and set up columns of attributes based on the information we have on the cards, i.e. call number, agency, title and date etc. To complete this step, I have to know some basics of creation and manipulation of database. I took Jeremiah’s suggestion to spend a while learning the Postgre SQL Languages and Server Administration. It turned out to be very useful in my second week’ work.
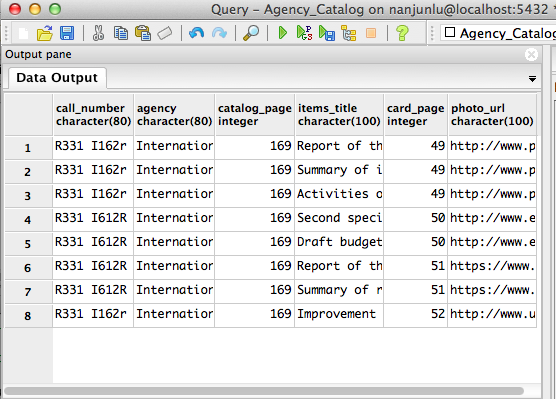
That’s the conclusion of my first week’s work , I’ll keep my progress updated and see you next week!
Cheers!
Nanjun