Hey!
I am Harsh Vardhan Tiwari, a first year Master’s student in Financial Engineering student, I am working on web scraping, which is a technique of writing code to extract data from the internet. There are several packages available for this purpose in various programming languages. I am am primarily using the Beautiful Soup 4 package in Python. There are various resources available online for exploring the functionalities within Beautiful Soup, but the 2 resources I found the most helpful are:
- http://www.crummy.com/software/BeautifulSoup/bs4/doc/
- Web Scraping with Python: Collecting Data from the Modern Web by Ryan Mitchell
My project basically involves writing a fully automated program to download and archive data mostly in PDF format from about 80 webpages containing about a 1000 PDF documents in total. Imagine how boring it would be to download them manually and more so if these webpages are updated regularly and you need to perform this task on a monthly basis. It would take us hours and hours of work, visiting each webpage and clicking on all the PDF attachments on each webpage to perform this task. And even worse if you have to repeat this regularly! But do we actually need to do this? The answer is NO!
We have this powerful tool called Beautiful Soup in Python that can help us automate this task with ease. About a 100 lines of code can help us accomplish the task. I will now give you an overall outline of how the code could look like.
Step 1: Import the Modules
So this typically parses the webpage and downloads all the pdfs in it. I used BeautifulSoup but you can use mechanize or whatever you want.

Step 2: Input Data
Now you enter your data like your URL(that contains the pdfs) and the download path(where the pdfs will be saved) also I added headers to make it look a bit legit…but you can add yours…it’s not really necessary though. Also the BeautifulSoup is to parse the webpage for links

Step 3: The Main Program
This part of the program is where it actually parses the webpage for links and checks if it has a pdf extension and then downloads it. I also added a counter so you know how many pdfs have been downloaded.

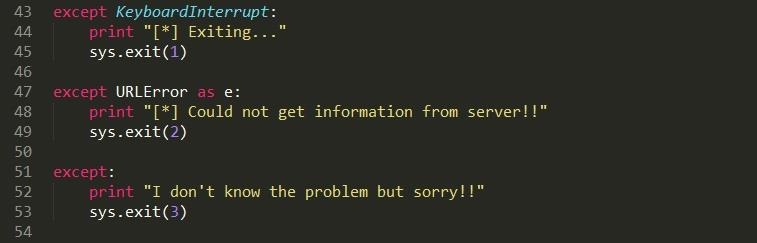
Step 4: Now Just to Take Care of Exceptions
Nothing really to say here..just to make your program pretty..that is crash pretty XD XD
Conclusion
This post covers the case where you have to download all PDFs in a given webpage. You can easily extend it to the case of multiple webpages. In reality different webpages have different formats and it may not be as easy to identify the PDFs and therefore in the next post I will cover the different formats of the webpages that I encountered and what did I need to do to identify all the PDFs in them.
Thanks for reading till the end and hope you found this helpful!