My project concerns the retrieval and display of digitally encoded music scores in existing archives and databases. While there are currently a great number of scores available in digital format, those formats differ, affecting not only their utility and but also their portability.
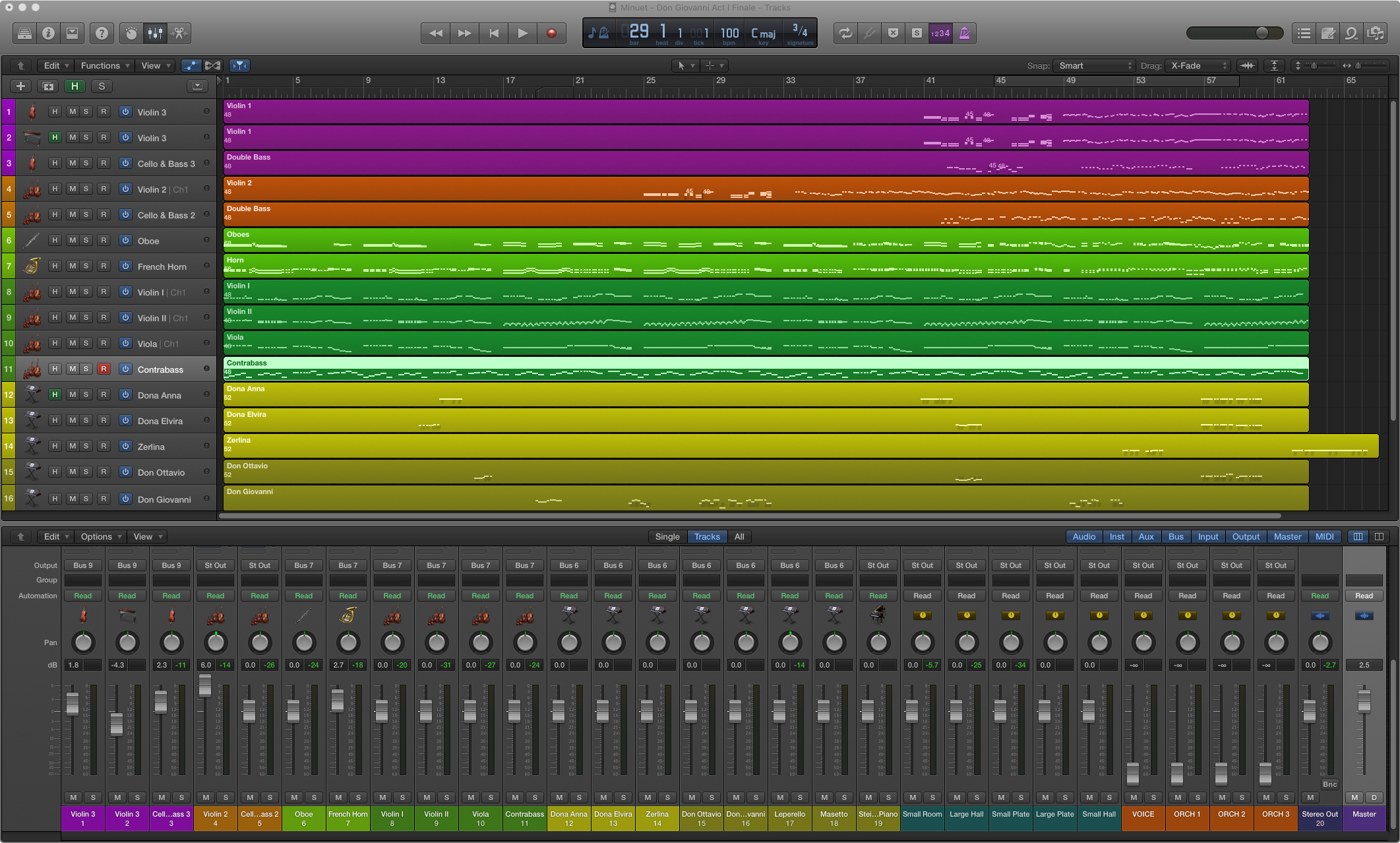
I recently made an attempt at working around this portability issue while trying to devise a demonstration for an undergraduate music humanities class this past semester. I had wanted to isolate and play back small groupings of instruments playing separate dances in different meters and show how Mozart was able to weave them together for the Act I climax of Don Giovanni. Though I ended up with a successful and visually appealing demonstration, it was a labor intensive process, not feasible to do with other pieces without vast reserves of preparation time. Below is the interface of an audio program, Logic Pro, that allowed me to arrange the different instrumental and vocal parts into separate tracks, and then assign each group to its own fader. I could then isolate and play the individual dance tunes and show how they blend together.
{kind=link}

What made the process so time consuming was the lack of a machine readable copy of the score. Creating this example required entering the notes from the score into a music notation program, and then translating that information into a midi file, which could then be read and played back by Logic Pro. Consumer software programs that produce formatted sheet music are readily available and are well suited to their primary task of creating and editing scores. They are not so good at importing scores from an outside source or for playing anything back. One of these notation programs, Sibelius, can import direct scans of sheet music and export them in a variety of formats. For import, it uses an optical music recognition plugin, comparable to the more familiar optical character recognition technology used for text files.
That any program can even approximate the job of converting lines, dots, symbols and text of an engraved music score into a digitally editable format is a minor miracle. But more often than not, the results using the Sibelius plug-in are just too flawed to use, making the time consuming task of manual entry the only reasonable way to access Sibelius’s processing and document translation features.

Hundreds of hours of work could be saved if previously encoded music scores could be used for such demonstration purposes. It would also be useful if there were a program that could play back those scores so that a separate audio file of a performance of the piece would not be needed. (Sibelius does have a playback feature; however, the program itself can be slow and somewhat unwieldy, using such a large portion of the computer’s resources that its performance is too sluggish to make it a useful tool for dynamic classroom demonstrations.)
The availability, then, of a repository of public domain scores in digital format would be a highly prized resource—not only for instructors, but researchers as well. To be able to quickly locate individual instances of musical structures in a given corpus, identify their context, and tabulate their frequency, would grant a degree of rigor and generalizability to analytic observations that can be difficult to achieve in music theory.
Such archives of digital scores do exist, but accessing those scores and being able to use them are two different tasks. In addition, different modes of digitization allow for varying degrees of analytic access. Some archives, like the International Music Score Library Project (IMSLP), store image files of score pages. These image files are not analyzable by machine unless further coded into some hierarchical data structure. As such, they present the same import difficulties noted above: they need to be scanned, and the optical technology does not yet exist to do that efficiently. Collections of midi files also exist, which contain the information necessary for producing an audio simulation of the notated music, but do not necessarily contain all the information indicated by a score (for example, expressive markings, articulation symbols, and other instructions to the performer).
MEI—the Music Encoding Initiative—is emerging as a standard format that will allow analytic processing. Any discussion of computer-assisted musicology needs to take this project into account. However, as this is a newer format, readily available instructional materials are few. Training is accomplished primarily through on-site workshops; user-friendly editing and display software is not available. I decided, therefore, to begin by looking at another widely used format, MusicXML, and the set of programming tools designed by and for academic researchers to work with that format, Music21.
MusicXML is a file format that allows for a representation of the elements in a score to be shared among various programs and platforms. And conveniently, Music21 comes packaged with a sizable corpus of over 500 scores to begin working with. Though designed to be easy to use, Music21 assumes a fairly sophisticated computing background on the part of the user, as difficulties in installation, utilization, and troubleshooting often arise. So while the package is well supported with online documentation, learning to use its contents is not the same as starting out with a consumer software product, safe in the knowledge that a little thoughtful clicking around, along with some methodical exploration of drop down menus, will eventually yield the desired results. Music21 is for coders. And the main drawback with Music21 is that the package requires a more than passing familiarity with its coding language: Python.
Python is a programming language that is relatively quick to learn. Nevertheless, it does require a certain amount of time and practice to get up to speed. Fortunately, the Digital Social Science Center offers a programming workshops designed specifically to help scholars analyze big data. The weekly sessions led by a computer science graduate student allow participants to get their feet wet and encourage outside practice. Its programs are designed specifically for scholars in my position: researchers needing to develop project-specific tools that will enable them to take advantage of the ever growing body of digital data that is made available to the public.
Below is an example of my latest programming efforts.

Two things are notable about this.
- Often, learning is best accomplished through actual hands on work. While I consider this program a success in many ways—most significantly, in that it didn’t just return an error message—it surprisingly did not return any notes with accidentals. That is because of the coding strategy used by MusicXML: a note’s identity as sharp or flat is stored separately from its letter name. This is crucial information to know; in fact, a note’s pitch in MusicXML is represented by a letter name, plus an octave designation, plus an optional “alteration” attribute of +1 or -1 (sharp and flat, respectively). Although explained in the documentation on the website for MusicXML, it’s programming experiences like these that really allow the data structure to be internalized.
- Note how easy it would be to fall into the trap of devising research questions based on the capabilities for information retrieval. Though perhaps a bit obvious, this provides a very clear example of how the organization of the data and the design of the programming language facilitate the accumulation of numeric facts which can end up directing further inquiry: “Bach’s Brandenburg Concerto No. 5 has 10,539 notes! I wonder if No. 6 has even more?” In order to take advantage of the depth of detail that is represented in the MusicxMXL format, it is important to guard against this tendency and instead continue to develop more refined programming skills.
The learning curve for Python, as is true for any language, is long and shallow—the programming results presented above may look rather paltry when compared to those attainable by experts in computer-assisted musicology. But as a scholar working independently to acquire new skills and gain access to recently developed research tools, they represent a lot of digging, exploring, and evaluating the programs, standards, and methods involved in storing music as a text file—in addition to the basics of learning a programming language. The analogy of language learning here is especially apt. Deciding to work with a corpus of computer encoded music scores for a research project is like deciding to work with a community of musicians in another region of the world. A new set of communication skills needs to be acquired, often from scratch, and a significant amount of time must be set aside for getting up to speed in the language.
While I continue to use this project as an opportunity to develop my own coding skills so I can make use of existing digitized corpora, I also intend to lay out exactly:
- what resources need to be made available to other graduate student researchers,
- what skills they will need to acquire in order to make use of those resources, and
- how much time they should plan on devoting to acquiring those skills.
One thought on “Digital Archives and Music Scores: Analysis, Manipulation, and Display”-
Pingback: Digital Archives and Music Scores: Analysis, Manipulation, and Display | Music & Arts Library News