The first blog for “plm” package provides basic information about how to define panel data. This blog aims to introduce syntax for both fixed and random effects regression models.
The dataset “Grunfeld” is a balanced panel of 10 observational units (firms) from 1935 to 1954, and we are going to use this dataset to run both fixed and random effects models. You could go back to the first blog and know how to load this dataset.
Firstly, we define the panel data as “Grunfeld_panel”
Grunfeld_panel <- pdata.frame(Grunfeld, index = c(“firm”, “year”))
- Fixed effects
grun.fe <- plm(inv ~ value + capital, data = Grunfeld_panel, model = “within”)
summary(grun.fe)
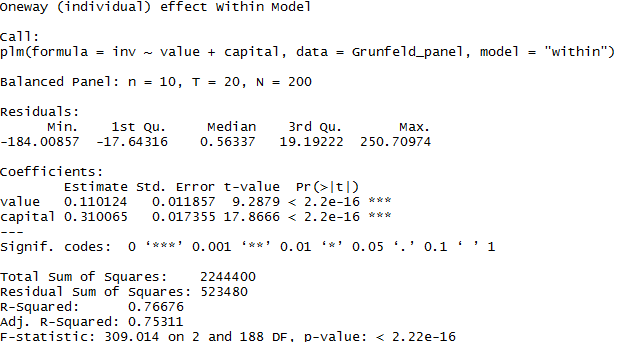
- Random effects
grun.re <- plm(inv ~ value + capital, data = Grunfeld_panel, model = “random”)
summary(grun.re)
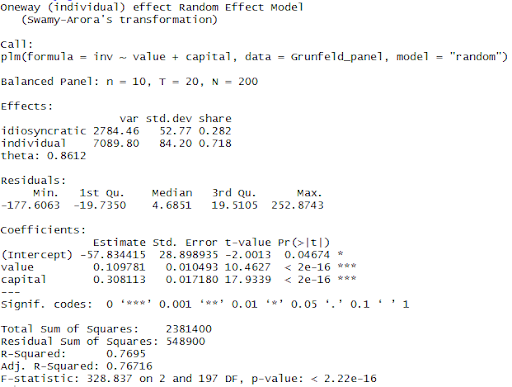
The model argument here, could be “within” (for the fixed effects model), “random” (for the random effects model), “pooling” (for the pooled OLS model), “fd” (for the first-differences model) and “between” (for the between model).