By Amanda S Bielskas, Director of Science, Engineering and Social Science Libraries ;
Emily Holmes, Director, Preservation ;
Esther M. Jackson, Scholarly Communication Technologies Librarian ;
Melanie Wacker, Metadata Coordinator ; and
Jeremiah Mercurio, Head, Humanities & History / Interim Director of Digital Scholarship
Columbia University Libraries has a robust digitization program that aims to preserve fragile collections and to increase their accessibility and discoverability. The Lamont Doherty Earth Observatory (LDEO) Technical Reports, a set of scientific reports dating from 1949 to 2003, are a grey-literature collection representing a unique set of materials that encapsulates important ecological research that remains pertinent to our current understanding of climate change. To digitize this collection, our team had to adapt existing libraries workflows to accommodate a new data source and this specific physical collection. LDEO is an active Library user community and partner, and digitizing this collection was a great opportunity for collaboration. Therefore, a cross-departmental team of 21 people at Columbia University Libraries set out to creatively adapt existing workflows and to digitize 298 of these technical papers comprising 32,597 pages and including 151 foldouts of various sizes, for the purpose of sharing them openly with the public through a suite of collections-based websites. Metadata was already largely available for these works through WorldCat (a union catalog that includes records from many libraries around the world) and for this reason the team devised a workflow that enabled the team to reuse that existing MARC metadata and at the same time increase access and visibility of these resources by making them digitally available through WorldCat, HathiTrust, CLIO (Columbia’s local integrated library system [ILS]), Internet Archive (IA), and Academic Commons (AC), Columbia University’s digital repository.
The goals of this project were to:
- Unhide/make items discoverable in CLIO and WorldCat
- Provide long term preservation of the intellectual content of the documents
- Determine where/how to host items (Academic Commons, IA, Hathi)
- Clarify duplication policy (if items were hosted in multiple locations)
- Collaborate with the University on the Year of Water (2020)
The project team adapted existing workflows for this project, which included digitization of the original print reports, cataloging of the physical and digital copies, and dynamically crosswalking (via HySync, an internal application) the MARC metadata from the ILS to a MODS-based format in Academic Commons, where the reports were assigned DOIs and made available for download.
The LDEO Technical Reports were essentially a hidden collection, as most of the material was not in Columbia’s local catalog. The Technical Reports were published in-house at Lamont and captured and documented the scientific data that was collected on the research cruises and expeditions. These reports were often required to partially satisfy funding agencies reporting requirements, and they document the expedition objectives, present the data that was collected, and the methods used in the collection. The reports often include: maps, charts, and tabular and other displayed data, including foldouts and additional sheets of varying dimensions. Some of the reports were created in conjunction with government agencies. This collection had not been collected, cataloged, or digitized systematically, and was at risk for loss without the Libraries’ intervention.
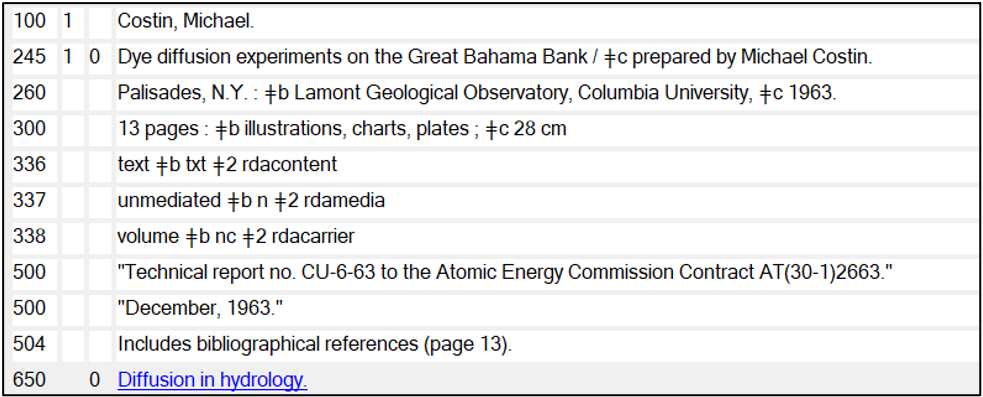
At Columbia University Libraries, the regular cataloging workflow for Academic Commons (AC) is independent from the general cataloging departments, which follow widely accepted library cataloging standards such as Resource, Description & Access (RDA) and use Library of Congress Name Authority (LC/NAF) access points. AC cataloging is done under the supervision of AC staff and follows more local guidelines or those in line with other research repositories. AC cataloging uses a MODS-based schema and a locally-created cataloging application called Hyacinth, which handles digital assets across many units of the Libraries. However, during the project planning process, we realized that while we had owned the original physical reports for a while, not all had been added to the Columbia University Library’s catalog, CLIO. The cataloging department set to work and downloaded all existing MARC records into our local catalog and also created original MARC records for the reports that had not yet been cataloged by another institution.
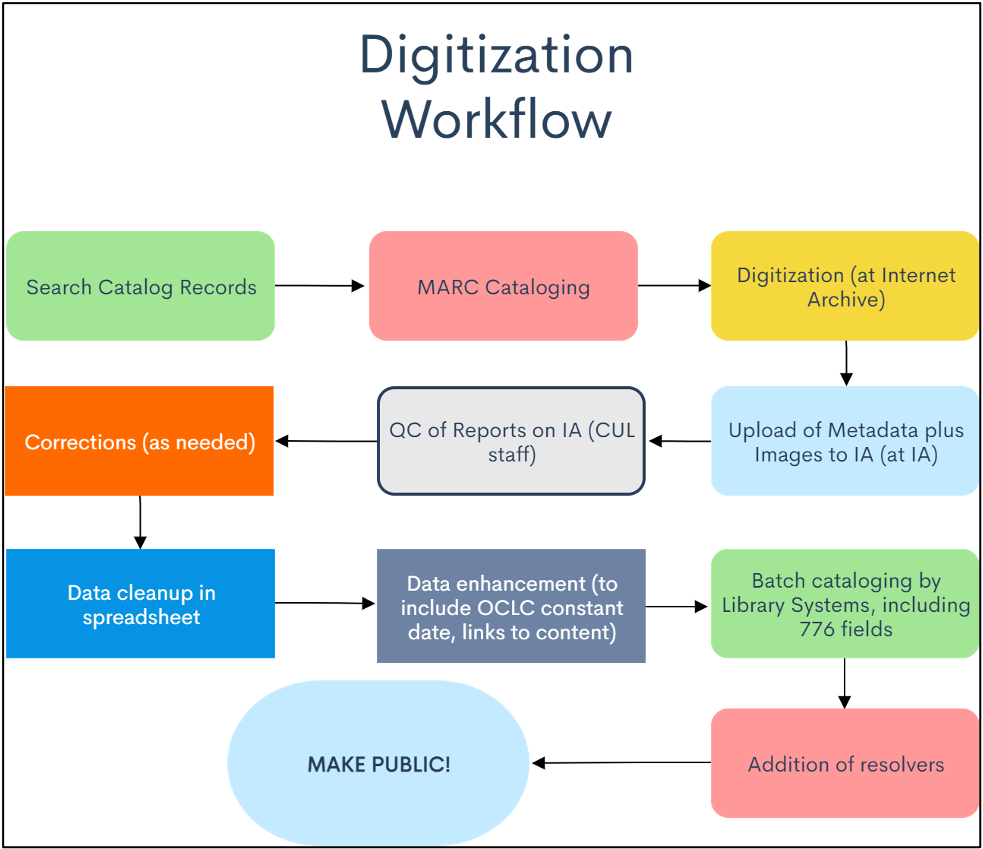
Once cataloging of the original materials was complete, the Preservation Division gathered this dataset into a CSV manifest, which was sent to Internet Archive (IA) in Princeton, NJ. The pamphlets were organized into labeled folders corresponding to item-level metadata on the CSV. IA scanned and uploaded the materials, along with MARC metadata extracted via Z39.50. 100% quality control of both metadata and page images was done in the Preservation Division, who then requested any necessary corrections be made at IA. After corrections were made, staff cleaned up the CSV file, now populated with IA links, and sent it, along with the appropriate OCLC template fields for e-books, to Library Systems, who cataloged all as a batch and added the URL resolvers. Resolvers simplify link maintenance, for example when a domain name changes or when it is necessary to redirect users to the proxy server for licenced e-resources. They then sent the full list to the Digital Scholarship department, which downloaded the PDFs directly from IA.
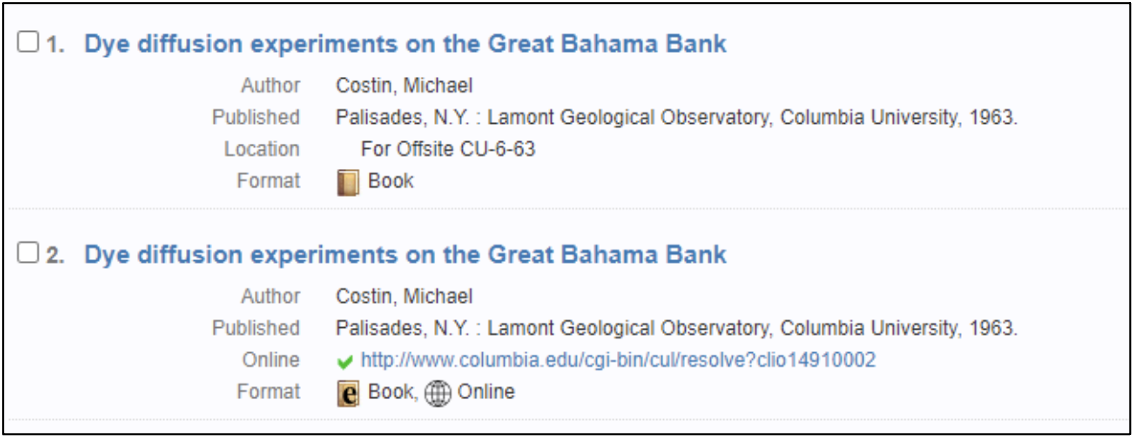
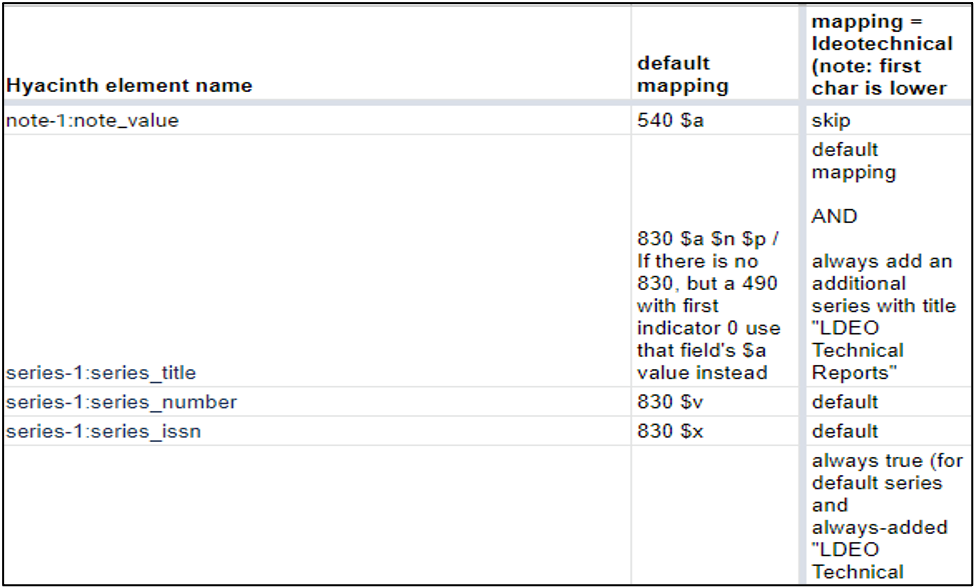
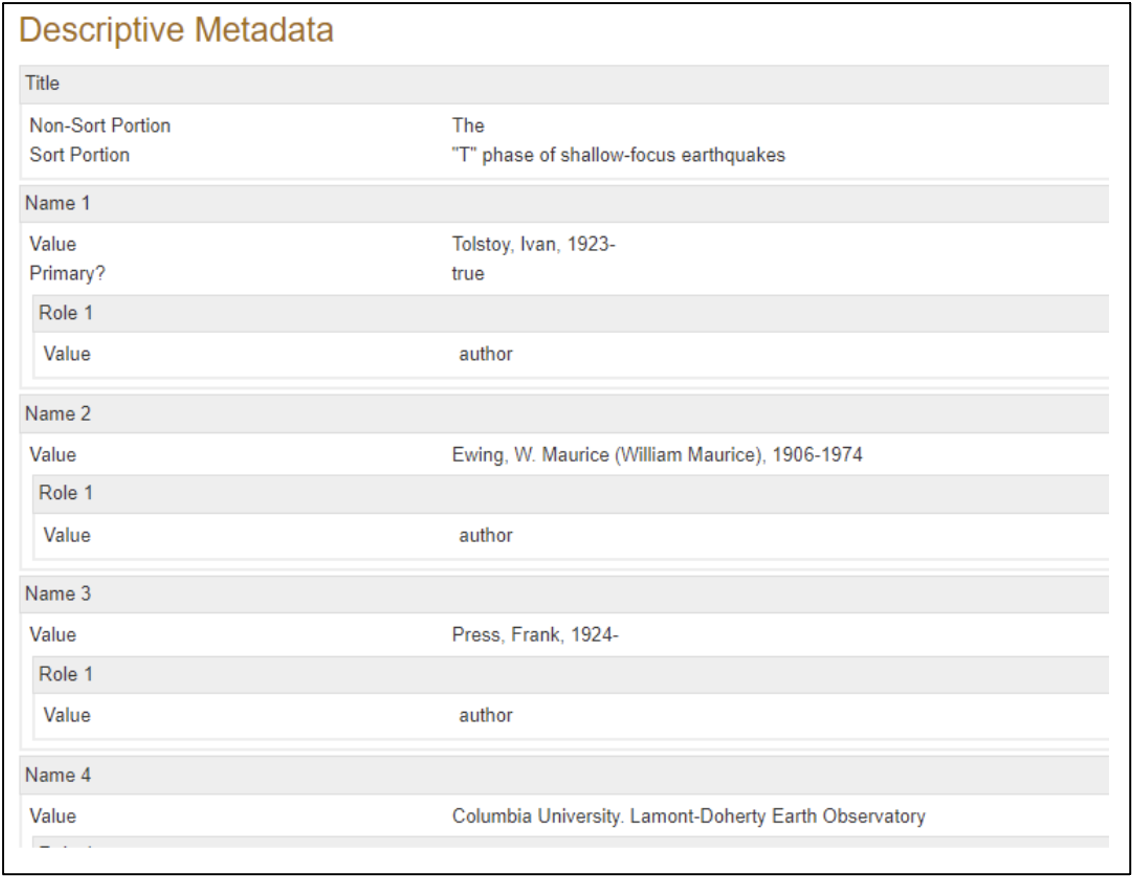
We then had metadata for all digitized reports in the MARC-based catalog, but the project’s overriding goal was to provide access to the digitized reports through Academic Commons, which uses the MODS metadata schema, and not MARC. We needed to move the metadata from one system to the other without any re-keying. The Libraries frequently reuses MARC data for other digital projects, and a mapping table and script already existed for those projects; however, this was the first time that we had to employ a crosswalk of this kind for Academic Commons, so both the mapping and the script had to be adjusted. The image above shows a small part of the mapping for Voyager (MARC) to Hyacinth. It also illustrates one of the biggest issues that had to be overcome. The MARC cataloging is based on national and international standards that were designed to facilitate data exchange between libraries; therefore, we try not to diverge from those standards when we create records in OCLC. Academic Commons, however, can’t utilize the information contained in external authority records in the same way that the other Libraries’ discovery systems can. Consequently, AC can’t rely on updates to those external authority records to keep fields—such as the name of the publisher series—up to date and to pull variant series names together under one set of records. To get around this issue, the Libraries’ development team (DIAG) created a workaround that hard-codes an additional local series title into the conversion from MARC to MODS. This functionality has proved useful for the Lamont Technical Reports series, which has in fact changed names many times over the course of its existence.

Beyond the immediate success of making the LDEO Technical Reports widely available to the public on many different Libraries platforms, this project has been successful in other ways. This workflow has been used with success to digitize other collections that are physically similar (for example, pamphlet-like collections that had already been cataloged in CLIO). Additionally, this project can now be given as an example to campus partners who may be holding similar ephemeral grey-literature collections that could be preserved and made more accessible in Academic Commons.
The project has also led to enhancements to Academic Commons as a system. We now have ways to indicate related items through our MODS templating, and we plan to add links from Academic Commons to records in CLIO and IA to indicate for users and indexes, like Google Scholar, that these works are the versions of each other. We also hope to use the HySync application in a project to connect Dryad Data to Academic Commons.
From when the project concluded until September of 2020, until the end of March 2022, the items have been viewed more than 10,000 times in Internet Archive, from patrons all over the world, including the United States, Japan, Australia, China, the United Kingdom, and Canada. In Academic Commons, the reports have been viewed more than 5,000 times, and downloaded more than 13,000 times. In the Internet Archive collection, the most popular report is Updated position and ice velocity for the AIDJEX manned camps. volume 1. 11 April 1975 to 17 October 1975. The most popular report in Academic Commons is Arctic Ice Dynamics Joint Experiment 1975-1976 : physical oceanography data report : profiling current meter data.
While we cannot say at this juncture exactly how these reports are being used, it seems reasonable to assume that some of the reports are being used in relation to current climate change research, a usage that we are excited to have helped facilitate.
With thanks to the additional following collaborators:
Nicky Agate, Jasmine Bhonsly, Rob Cartolano, Chris Cronin, Eva Cunningham, Enerel Dambiinyam, Stephen Davis, Kate Harcourt, Violeta Ilik, Charlotte S. Kostelic, Brian Luna Lucera, Jeremiah Mercurio, Dave Motson, Eric O’Hanlon, Kathryn Pope, Crystal Rivas, Barbara Rockenbach, Mark Wilson