By Timothy Ryan Mendenhall and Matthew Haugen
Background on Digital Scriptorium
The Digital Scriptorium (DS) is a consortial database of pre-modern manuscripts held in American libraries. Started in 1997, Digital Scriptorium was originally a joint project of the Bancroft Library at University of California Berkeley and the Rare Book and Manuscript Library here at Columbia University. RBML’s contribution was led by Consuelo Dutschke, the former Curator, Medieval and Renaissance Collections. The database included detailed descriptions of the manuscripts, along with selected digital images. By 2015, the database had catalog records for over 8,000 manuscripts and nearly 50,000 images from over thirty member institutions across the country. As the consortium grew, Columbia and Berkeley continued to host the technical infrastructure of the database at various times. Manuscripts belonging to other Columbia repositories and affiliates besides RBML, including the Barnard College Library, the Burke Library at Union Theological Seminary, the Gottesman Libraries at Teacher’s College, and the Arthur W. Diamond Law Library at Columbia Law School, were also added to the database over time.
Each DS record included metadata not only about the textual content of the manuscript, but also its date and place of origin, provenance, physical construction, and details of script, layout, and decoration to aid in identification and comparison. For example, comparison of images and descriptive details could allow a scholar to determine whether separate manuscripts were produced in the same scriptorium or even by the same scribe. Or, fragments or leaves from the same manuscripts dispersed across different institutions could be matched and virtually reconstituted into the complete manuscript.
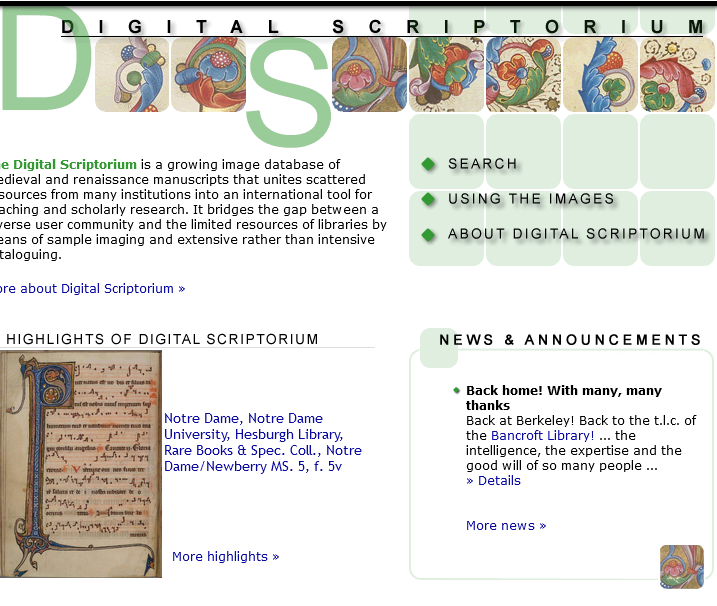
Data Model
In the original Digital Scriptorium, a hierarchical data model was developed to account for the complexity of manuscript materials. To our contemporary sensibilities, we tend to regard a volume as a discrete intellectual unit. Bound manuscripts, however, may consist of parts brought together from different places and times which for any number of reasons may end up bound in a single volume. Each part may itself contain a compilation of different texts by different authors. Within the original DS, description of each text might have been accompanied by scans of individual pages, parts, or illustrations. As such, the original data model was arranged into six parts, given in descending hierarchical order: host or volume, part, text, item, page, and image (equivalent to the digital file). This data model was expressed using the METS (Metadata Encoding and Transmission Standard) XML schema, which brings together descriptive, administrative, and technical information with details of related digitized files and their structure. Notably, METS is a standard which allows for the incorporation of metadata from other XML schemas.
Within the METS structure, the descriptive metadata contains most of the information displayed to users searching the Digital Scriptorium catalog, including elements like title, place of origin, date of production, various notes, and contributors such as authors and scribes. This descriptive metadata is expressed in the MODS XML schema, which is closely aligned with the MARC encoding standard used in most library catalogs. The MODS description is wrapped inside of the METS description. In most cases, each discreet manuscript item in the original Digital Scriptorium would have multiple MODS descriptions, representing different levels of the DS1.0 data model, wrapped inside a single METS document. Even a simple broadsheet thus had a minimum of three MODS descriptions, representing the volume – part – text levels in the DS 1.0 data model.
The structural map section of the METS document contains information about the hierarchy and sequencing of the MODS descriptions and of any files, typically digitized pages from the manuscripts, associated with each item in Digital Scriptorium. This structural map then determines how the different descriptive elements and digital files were displayed in DS 1.0.
The new version of Digital Scriptorium, known as DS 2.0, has a radically different data model informed by linked open data standards developed only in the decades after the original Digital Scriptorium was created. We will cover this data model in the following section. In the meantime, we are excited that we are adding over 1000 records for Columbia’s medieval and Renaissance manuscript holdings to CLIO and WorldCat, and we hope that this helps make these unique treasures more findable!

DS 2.0
In 2020, Digital Scriptorium was awarded a grant by the Institute for Museum and Library Services (IMLS) to reconstitute the DS database. Led by the University of Pennsylvania, the Digital Scriptorium 2.0 project (DS 2.0) seeks to aggregate metadata directly from member repositories and present that data in a Linked Open Data format.
In addition to changing host institutions, DS 2.0 represents a major structural change from DS 1.0, such that the original DS 1.0 data is not being directly repurposed into the new database. While DS 2.0 remains in development, the original database, now known as DS 1.0, was taken down in early 2022. The images and descriptive data from DS 1.0 are instead being preserved on Internet Archive.
Meanwhile, of the approximately 1,600 manuscripts from Columbia collections that were represented in DS 1.0, less than 10% of them also had records in CLIO. For the remaining 90% of manuscripts, Columbia staff worked to convert DS 1.0 data into Machine Readable Cataloging (MARC) records to be added to CLIO, so that they can subsequently be reincorporated into DS 2.0. Additional manuscripts in our collections that were not originally included in DS 1.0, such as some of the manuscripts from the Muslim World Manuscripts project, may also be incorporated into the new DS 2.0 database for the first time. This takes advantage of other cataloging and digitization work completed at Columbia separately from DS 1.0 since its inception. It also represents an expansion of the scope of DS 2.0 beyond manuscripts belonging primarily to the western European scriptorium tradition. DS 1.0 entries frequently included only sample images, and DS 2.0 will not host images at all. Nonetheless, fuller digitization of our medieval and renaissance manuscript collections according to current standards may be pursued in the future.
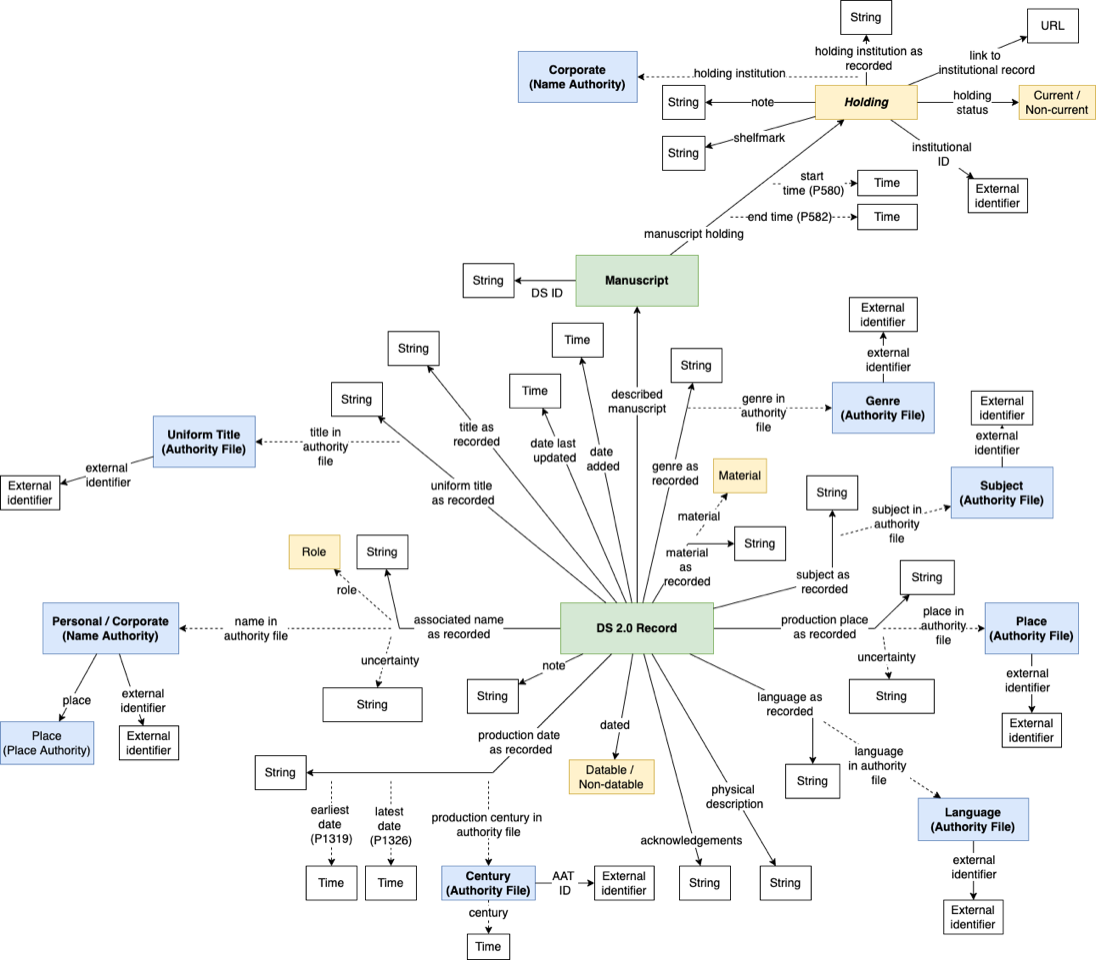
As described above, DS 1.0 used a data structure expressed in the METS XML schema. DS 2.0 will host its descriptive data in Wikibase, which is a linked-data friendly platform known as the software that powers Wikidata, a structured-data sibling of Wikipedia. Wikibase incorporates a linked-data friendly data model where all data fields (or properties) and most values in data fields are assigned unique URIs. Each URI represents an entity that can have one preferred label per language, as well as variant labels and descriptions in multiple languages. In practice, updating the preferred label(s) for an entity/URI will automatically update any use of those labels throughout the database, which greatly reduces the overhead needed for database maintenance. This data structure also can support multilingual, multi-script access based on end-user preference.
Notably, the data model used for DS 2.0 mostly dispenses with the volume – part – text hierarchy. For practical purposes, the new data model in many regards represents a flattening of the DS 1.0 metadata into a more document-like structure that aligns more closely with MARC-based descriptions in library catalogs. There are two primary entities in the new model — Manuscript and Record. The Manuscript entity represents the physical object which has a holding associated with an institution, a shelfmark (something like call number), and a few other mostly administrative data elements. Meanwhile, the Record entity contains most of the descriptive details about the object, that were housed in the various MODS descriptions associated with a manuscript in DS1.0. In the new model, it could still be possible to have multiple descriptions (or Record entities) point to a single Manuscript entity. In practice, however, institutions contributing data can set up a syncing process so that the DS2.0 data store remains in alignment with their institution’s catalog data, typically in MARC records. For the Columbia’s manuscript records converted from DS1.0, this will for the time being mean a more flattened descriptive presentation.
Conversion
Given the ongoing migration of the Digital Scriptorium platform, and the fact over 90% of CUL’s manuscripts holdings did not yet have searchable records in our library catalog, our primary task during this project has been to extract the relevant metadata from the METS files exported from the original Digital Scriptorium, and to convert it into the MARC format used by our library catalog CLIO. These MARC records can also be shared with WorldCat, increasing the visibility and reach of CUL’s manuscript holdings.
The conversion took place in three main phases: extracting the descriptive metadata and the descriptive structure from the METS file, data restructuring and cleanup in OpenRefine, and final conversion to MARC.
While extracting the MODS descriptions from the DS1.0 METS files seemed like a straightforward task, the complexity of the DS1.0 data model and its expression in the METS structure made this task a bit trickier. But first, to begin work, metadata librarian Ryan Mendenhall had to download the 1600 METS descriptions from the Digital Scriptorium website, which he did using a Firefox browser extension called Simple Mass Downloader. Since one goal was the batch processing and cleanup of the records, it would be necessary to compile all the MODS descriptions into a single file rather than hundreds of files.
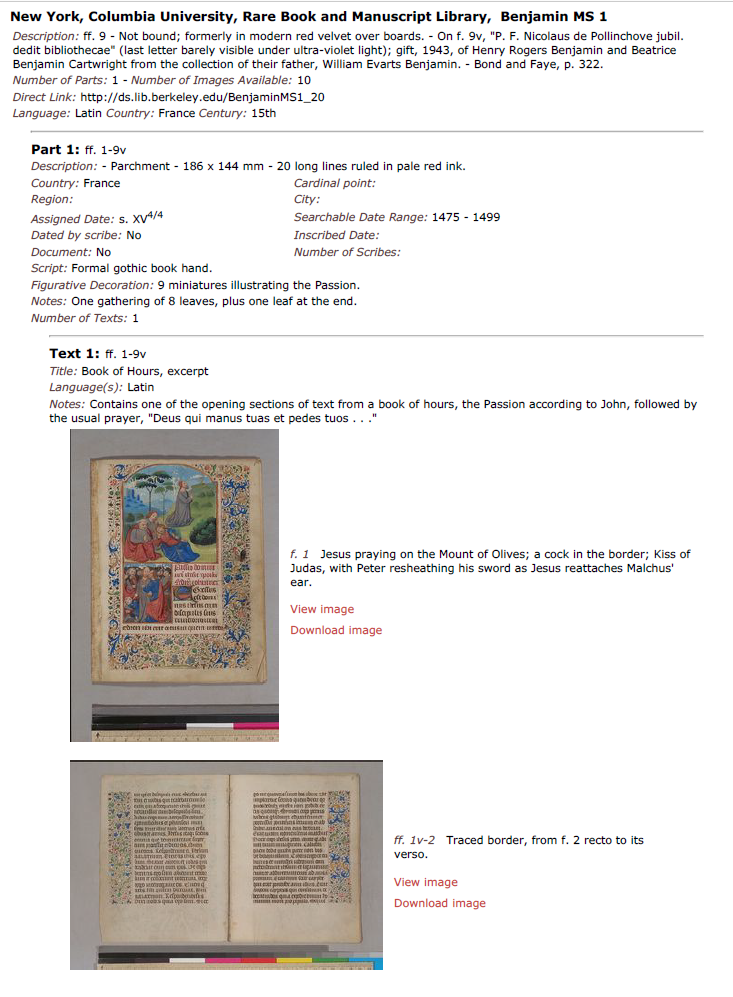
For the MODS transformation, XSLT (EXtensible Stylesheet Language –Transformations), a standard for transforming XML files, was used. The XSLT stylesheet was written to work on an entire directory of files, rather than a single file, and transform them into a single MODS file containing discrete records for each manuscript. After reviewing the MODS output of initial drafts of the stylesheet, rare books cataloger Matthew Haugen, in consultation with manuscripts curator Emily Runde, determined that MODS descriptions associated with items, pages, and images in the DS1.0 data model could be omitted from the output. Since these usually described digital images associated with the DS1.0 webpage, which in general represented only a small selection of pages from the manuscripts and did not meet current imaging standards, leaving these descriptions out would not result in any substantial data or knowledge loss. This still meant that each individual manuscript had at least three MODS descriptions associated with the three top levels of the DS1.0 data model: volume, part, and text. In theory it would be possible to create separate (or analytic) records for parts of a bound manuscript, but the team decided that the volume-level MODS would comprise the primary MARC description, and the part- and item-level MODS descriptions would be incorporated into this primary MARC record via the use of mods:related item elements, which like the MARC 775 field (“constituent item”) allows for a kind of nesting of part descriptions into the primary description. While most of the METS files had a fairly straightforward hierarchy, with a single volume, part, and text, about 230 had multiple parts and texts. Unfortunately, the various MODS descriptions themselves were not clearly marked in the source files, so the XSLT had to query the structural map in the METS to determine where the various MODS descriptions fit in relation to each other; the XSLT would add a mods:part element to each mods:relatedItem element to indicate the hierarchical level (part or text) and the order of each “child” description in the mods:relatedItem elements.
After reviewing this revised MODS output and making an initial conversion to MARC, Matthew still felt that more work needed to be done to unify the descriptions put into the “constituent item”/MARC 775 fields with the primary MARC description. Comparing the content of the related-item elements with the primary record description could only be done record-by-record, and it wasn’t possible to get an effective overview of what was being described at the volume, part, and text-level, although it was clear that in many instances different aspects of the manuscript were being treated differently at each level, and some descriptive elements occurred only at one of the three levels. In turn, this lack of an overview made it difficult to make a clear and comprehensive mapping from the original MODS/METS to MARC. To address this problem, Ryan generated a .csv version of the metadata using MARCEdit, and loaded this into OpenRefine, a useful application for cleaning up and transforming data. With OpenRefine we were able to align the descriptions at the volume, part, and text levels, and make better decisions about mapping from DS1.0 to MARC. We decided to pursue a plan to “flatten” the hierarchical description of DS1.0 when converting into MARC.
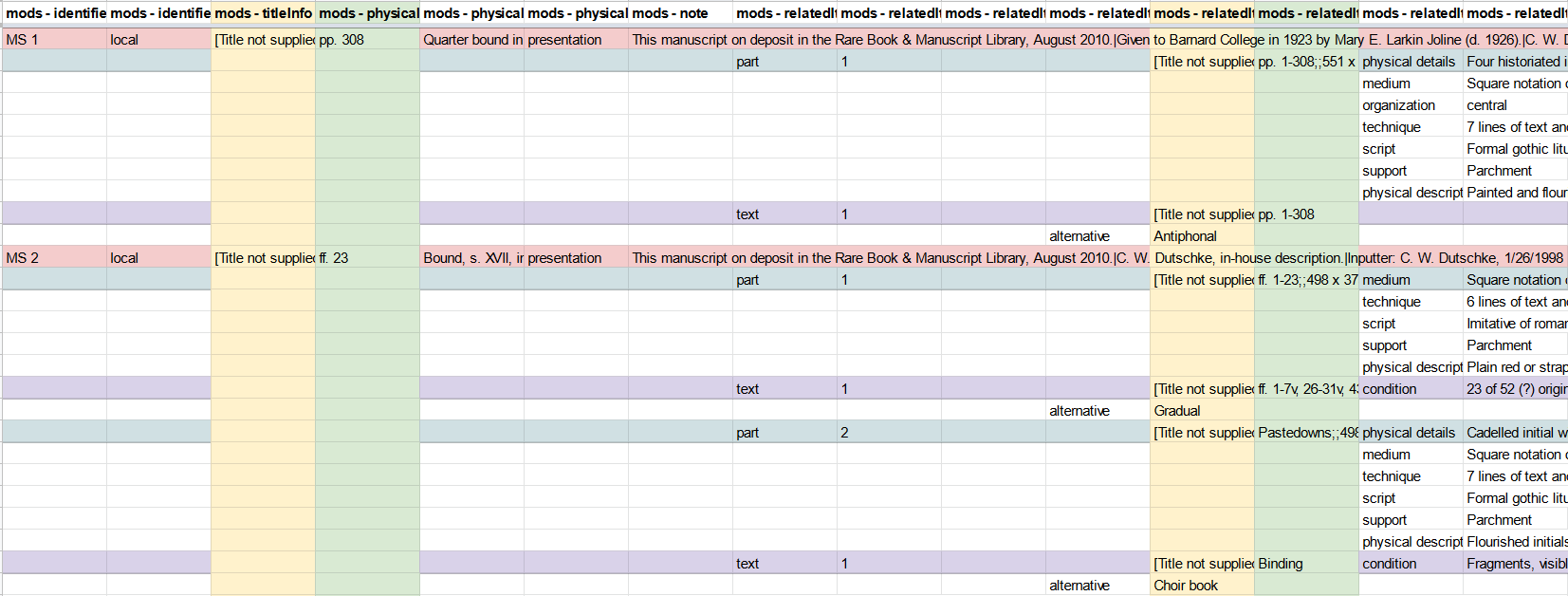
To illustrate, most descriptive elements, including title, authors/contributors, date and place of creation, extent, dimensions, and various notes all occurred at each level in the hierarchical description–volume, part, and text. In the initial MODS and MARC outputs, these various titles were scattered across title/245 and related item/775 elements. OpenRefine gave us the tools to see that titles were only supplied at the text-level–titles of parts and volumes all were marked “title not supplied.” We could also readily determine how many parts and texts each item had, and if there were multiple texts, we could see if the texts shared a title or had unique titles. The pagination provided at the volume, part, and text levels is also helpful for understanding the process of untangling the metadata. In the simplest example, a manuscript with a single part and single text would have something like this in the original metadata: volume-level: pp. 308; part-level: pp. 1-308 ; 551 x 384 mm; text-level: pp. 1-308. We can see that the pagination across the levels is pretty similar, but the dimensions are given at the part-level. So for most records, we took the pagination from the volume-level, and dimensions from the part-level to create the MARC 300 field. For multi-part and multi-text manuscripts, the item-level pagination was important. In rare book cataloging standards like AMREMM, you need this pagination to create a contents note for such complex items, and the item-level pagination is important to retain in notes, since in many cases notes apply to only the specific part/text of the manuscript, but not to other parts or to the manuscript as a whole.
Example of a contents note, bringing together text-level titles and extents from UTS Ms. 7:
505 00 $g ff. 1-24v $t Chronicon a tempore Moysis usque ad Vespasianum imperatorem / $r Jordanus, von Osnabrück (Author) — $g ff. 25-28 $t Ecclesiastical provinces –$g f. 28 $t Titles of cardinals — $g f. 28r-v $t Parts of the world — $g ff. 28v-32 $t De prerogativa romani imperii / $r Jordanus, von Osnabrück (Author) –$g ff. 32-35v $t Provinciale — $g f. 36r-v $t Letter, 9 May 1169
Example of MARC 500 notes which apply only to certain parts of the manuscript from UTS Ms. 7:
500 $3 ff. 1-24v $a Author: Jordanus Osnaburgensis?
500 $3 f. 28r-v $a Fuller version to be found in PL 177:210-213
With this better understanding of the mapping and how we could bring together the volume, part, and text descriptions, we were able to “flatten” the records using OpenRefine. No longer did we have a minimum of three lines per manuscript on our spreadsheet — each manuscript, no matter how complex, was now represented by a single line.
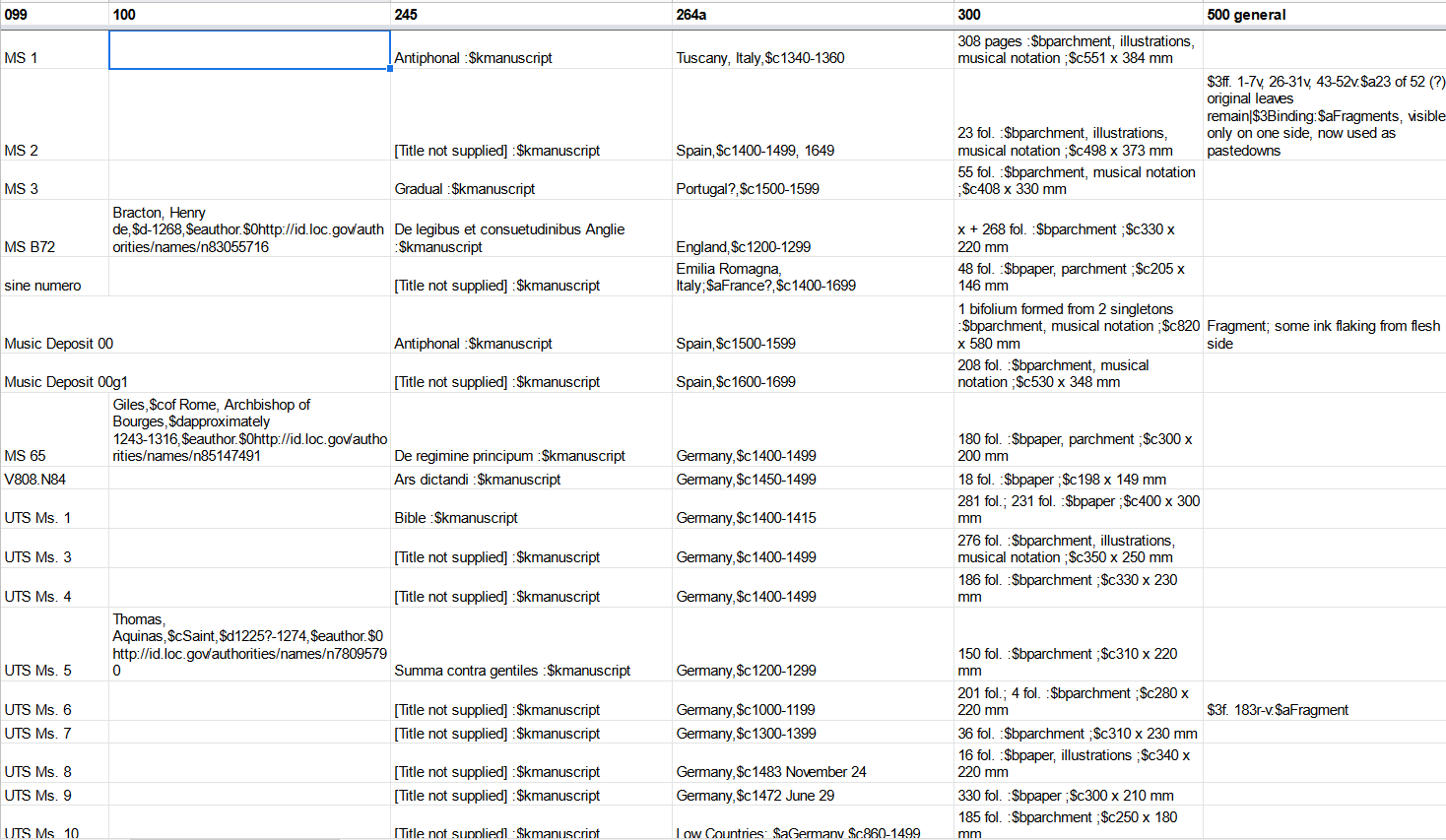
Prior to the flattening, we wanted to do some other batch manipulation and enhancement. Continuing on a previous example of the MARC 300 field, let’s look at the notes in the MODS export which had the types “physical description” and “physical details.” Almost all of these free-text notes included information about decoration and illustrative content, and were mapped to a 500 note with the textual prefix “Decoration: ” added to the note per the DCRM-AMREMM descriptive standard. However, in MARC records we also add terms for illustrative content to the 300 $b field, a code for the type of illustrations to the 008 field, and for certain types of illustrations, we add a 650 subject heading such as “Illumination of books and manuscripts.” OpenRefine allows you to set up filters for specific words, like “drawings,” “maps,” and “illuminations.” With such a filter in place, you can apply changes to the metadata only to the filtered rows which contain the words. This method allowed us to take a free-text note and add the appropriate terms to the 300$b, the appropriate codes for illustrations to the 008, and we also could add subject access points for things like manuscript illuminations to the 650 fields.
Other processes undertaken in OpenRefine included normalizing various metadata fields to match current standards, and adding URIs to access points like contributors and subject headings. As an example, since the DS1.0 was created, the Rare Book and Manuscript Section (RBML) of ACRL/ALA issued its Standard Citation Forms for Rare Materials Cataloging, which specify standardized forms of citations to use when citing common reference sources used for rare book bibliography. OpenRefine’s batch replacement functions made it easy to standardize citations in the metadata to match these Standard Citation Forms. Adding URIs to access points will help us bridge the gap between the MARC standard and the linked-data orientation of the DS2.0 data model, which relies on URIs for many data points.
After cleaning up and enhancing the metadata in OpenRefine, the metadata is exported and loaded into MarcEdit for final conversion to MARC. After this conversion, the records were ready to be loaded into Voyager. In early 2023, the records were loaded with the assistance of Charlotte Kostelic into Voyager and are now, at long last, searchable in CLIO. We hope that this will help increase discoverability of these valuable resources and help expose them to new constituencies. Now that they are in CLIO, they will soon be synced to WorldCat and reach an even broader audience.
Next steps
We are still waiting to find out more details about how data will be contributed to DS2.0 and how we can ensure that updates made locally are synced with DS2.0. However, based on presentations and discussions with DS2.0 staff in mid-2022, it seems likely that we will be able to sync data directly from our Voyager catalog to DS2.0 via a common MARC sharing protocol like Z39.50. In the meantime, many of the records generated from DS1.0 have placeholder values like “[Title not supplied]” when that information couldn’t be automatically constructed from the DS1.0 data. Matthew Haugen and Emily Runde are working to supply these titles and make other enhancements to the records over time, sometimes by consulting the actual manuscripts. Additional work needs to be done to determine which other manuscripts in our collections will be contributed to DS2.0 and which will not, based largely on date and place of production.