Literary mapping presents exciting possibilities for criticism and the digital humanities, but it is hampered by a seemingly intractable technical problem. A critic interested in mapping must rely on either full hand-coding, which takes too much time and labor to be useful at scale, or full automation, which is frequently too imprecise to be of any use at all. As a result, mapping projects are usually either narrow but reliable or broad but dubious.
I am therefore developing an interface that will combine the best aspects of both approaches in a process of semi-automated literary mapping. This interface will combine automatic pre-processing of text data, to identify locations and suggest geotags, with a backend framework designed to speed up the process of cleaning the resulting data by hand. The end product will work something like this: the interface prompts its user for a plain text file, then presents the user sequentially with each of the identified “locations”; for each of these locations, the user confirms whether it is indeed a location, and chooses among the top map hits from Geonames or a similar API; from here, other options are available, such as “Tag all similar locations” or “Categorize location” to add flexibility for individual projects. When the text has been fully processed, the results are presented as a web map and are exportable for use in GIS mapping software like QGIS or ArcGIS. The entire process is simple, but the gains in the speed and ease of mapping literary locations could be considerable.
While much work remains to be done, some of the fundamental backend components have already been built. I already have a working Python prototype of the automation process using the Stanford NLP Group’s Named Entity Recognizer and the Geonames API, which I presented in a workshop as part of Columbia’s Art of Data Visualization series in spring of 2016. I further developed and employed this prototype in a collaborative project studying the medieval Indian text Babur-nama. Using automatic location extraction and geolocation, ArcGIS, and some minor hand-cleaning of geodata by myself and my partners, my team detected clusters in point data from the text, deriving from these clusters a rough sense of the regions implicit in Babur’s spatial imagination (which contrast suggestively with the national borders in maps by colonial maps of the period).

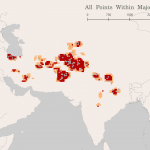
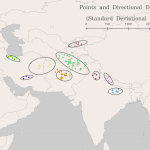
This project demonstrates the viability of the method while also underscoring the importance of preprocessing the data and expediting the hand-cleaning with geotag recommendations.
The next phases of the project will focus on building the framework and improving the location extraction and geotag recommendation algorithms. I will begin developing the interface itself, using either Flask or a combination of Django and GeoDjango for the interface’s skeleton. I will then incorporate the two elements of the automatic pre-processing that I have already developed: location recognition and Geonames-based geotagging. From here, I will turn to the “output” stage, allowing the data to be exported for use in GIS software and, hopefully, displayed in the framework itself. Finally, I will use the prototype in a test case from my own field of literary study, twentieth-century American fiction. If time remains in the year, I will devote it to developing methods to use previously input data to recommend a geotag, thereby making the pre-processing “smarter” the longer it is used.
For me, this is a project born of necessity: I need it for my own work, but it does not yet exist. I would be very surprised if I am alone in this. I am excited by this project, therefore, because I see it as achievable and as having the potential for significant impact in the field of literary mapping: if everyone else doing this kind of work is facing the same problems, an interface that helps them circumvent those problems could be a first step for many humanists working in this field.
I am a fourth-year PhD Student in the Department of English and Comparative Literature studying 20th-century American fiction, ecocriticism, and DH. I started working on location extraction and literary spatial data about a year ago; before that I was working on RogetTools, a Python framework for word categorization and semantic analysis based on Roget’s hierarchy of semantic categories. More at my website.